AI의 정의
인공 지능이라고도 하는 AI는 인간과 유사한 문제 해결 능력을 갖춘 기술입니다. 실제 AI는 이미지를 인식하고, 시를 쓰고, 데이터 기반 예측을 하는 등 인간의 지능을 시뮬레이션하는 것처럼 보입니다.
현대 조직은 스마트 센서, 사람이 생성한 콘텐츠, 모니터링 도구, 시스템 로그와 같은 다양한 소스에서 대량의 데이터를 수집합니다. 인공 지능 기술은 데이터를 분석하고 이를 사용하여 비즈니스 운영을 효과적으로 지원합니다. 예를 들어, AI 기술은 고객 지원 시 사람과의 대화에 응답하고, 마케팅을 위한 독창적인 이미지와 텍스트를 만들고, 분석을 위한 스마트한 제안을 할 수 있습니다.
궁극적으로 인공 지능은 맞춤형 사용자 상호 작용과 복잡한 문제 해결을 위해 소프트웨어를 더 스마트하게 만드는 것입니다.

AI 기술에는 어떤 유형이 있나요?
AI 앱 및 기술은 지난 몇 년 동안 기하급수적으로 증가했습니다. 다음은 여러분이 접할 수 있는 일반적인 AI 기술의 몇 가지 예입니다.
AI의 역사
Alan Turing은 1950년에 쓴 논문인 ‘Computing Machinery and Intelligence(계산 기계와 지능)’에서 기계가 사고할 수 있는지 여부를 고찰했습니다. 이 논문에서 Turing은 인공 지능이라는 용어를 처음 만들어 이론적, 철학적 개념으로 제시했습니다. 하지만 오늘날 우리가 알고 있는 AI는 수십 년에 걸쳐 많은 과학자와 엔지니어가 함께 노력한 결과물입니다.
1940년~1980년
1943년 Warren McCulloch과 Walter Pitts는 인공 뉴런 모델을 제안하여 AI의 핵심 기술인 신경망의 토대를 마련했습니다.
그 뒤를 이어 1950년 Alan Turing은 기계 지능을 평가하기 위한 튜링 테스트의 개념을 소개하는 ‘Computing Machinery and Intelligence(계산 기계와 지능)’을 출간했습니다.
이를 계기로 대학원생인 Marvin Minsky와 Dean Edmonds는 최초의 신경망 기계인 SNARC를 구축했고, Frank Rosenblatt은 신경망의 초기 모델 중 하나인 Perceptron을 개발했으며, Joseph Weizenbaum은 1951년부터 1969년까지 Rogerian 심리치료사를 시뮬레이션한 최초의 챗봇 중 하나인 ELIZA를 개발했습니다.
1969년부터 1979년까지 Marvin Minsky는 신경망의 한계를 입증했고, 이로 인해 신경망 연구가 일시적으로 쇠퇴했습니다. 첫 번째 'AI 겨울'은 자금 부족과 하드웨어 및 컴퓨팅의 한계로 인해 발생했습니다.

1980년~2006년
1980년대에는 주로 번역과 전사 분야에서 AI 연구에 대한 새로운 관심과 정부 자금이 쏟아졌고, 이 시기에는 의학 등 특정 분야에서 인간의 의사 결정 과정을 시뮬레이션하는 MYCIN과 같은 전문가 시스템이 인기를 얻었습니다. 1980년대 신경망이 부활하면서 David Rumelhart와 John Hopfield는 컴퓨터가 경험을 통해 학습할 수 있다는 것을 보여주는 딥 러닝 기술에 관한 논문을 발표했습니다.
1987년에서 1997년 사이에는 다른 사회경제적 요인과 닷컴 붐으로 인해 두 번째 AI 겨울이 찾아왔습니다. AI 연구는 더욱 세분화되어 다양한 사용 사례에서 분야별 문제를 해결하는 팀들이 생겨났습니다.
1997년부터 2006년경까지 IBM의 Deep Blue 체스 소프트웨어가 세계 체스 챔피언인 Garry Kasparov를 물리치는 등 AI 분야에서 상당한 성과를 거두었습니다. 이 외에도 Judea Pearl은 AI 연구에 확률과 의사 결정 이론을 포함하는 책을 출판했으며 Geoffrey Hinton 등은 딥 러닝을 대중화하여 신경망의 부활을 이끌었습니다. 그러나 상업적 관심은 여전히 제한적이었습니다.

2007년~현재
2007년부터 2018년까지 클라우드 컴퓨팅의 발전으로 컴퓨팅 성능과 AI 인프라에 더 쉽게 접근할 수 있게 되었습니다. 이는 기계 학습의 채택 증가, 혁신 및 발전으로 이어졌습니다. Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton이 개발한 AlexNet이라는 합성곱 신경망(CNN) 아키텍처가 ImageNet 대회에서 우승하여 이미지 인식 분야에서 딥 러닝의 힘을 보여주었고, Google의 AlphaZero는 사람의 데이터 없이 자가 플레이에 의존하여 체스, 장기, 바둑 게임을 마스터했습니다.
2022년에는 인공 지능(AI)과 자연어 처리(NLP)를 사용해 인간과 같은 대화를 나누고 작업을 완료하는 챗봇(예: OpenAI의 ChatGPT)이 대화 능력으로 널리 알려지면서 AI에 대한 관심과 개발이 다시 활발해졌습니다.

미래의 AI
현재의 인공 지능 기술은 모두 사전 결정된 파라미터 세트 내에서 작동합니다. 예를 들어 이미지 인식 및 생성에 대해 학습한 AI 모델은 웹 사이트를 구축할 수 없습니다.
인공 일반 지능(AGI)은 인간과 유사한 지능과 스스로 학습할 수 있는 능력을 갖춘 소프트웨어를 만들려는 이론적 AI 연구 분야입니다. 목표는 소프트웨어가 수행하도록 훈련되거나 개발되지 않은 작업까지 수행할 수 있도록 하는 것입니다.
AGI는 자율적 자제력, 어느 정도 자기 이해, 새로운 기술 학습 능력을 갖춘 AI 시스템을 개발하기 위한 이론적 추구입니다. 제작 당시에는 학습하지 못했던 설정과 상황의 복잡한 문제를 해결할 수 있습니다. 인간의 능력을 갖춘 AGI는 이론적 개념이자 연구 목표로 남아 있습니다. 이는 AI의 가능한 미래 중 하나입니다.

오늘날 AI는 어떻게 사용되고 있나요?
오늘날 AI는 어디에나 있으며, 사용자가 즐겨 사용하는 애플리케이션을 지원하기 위해 백그라운드에서 작동합니다.
비즈니스용 인공 지능 예
인공 지능은 다양한 응용 분야를 가지고 있습니다. 다음은 전체 목록은 아니지만, 조직에서 AI의 다양한 사용 사례를 보여주는 예입니다.
챗봇 및 스마트 도우미
AI 기반 챗봇과 스마트 도우미는 보다 정교하고 인간과 같은 대화를 할 수 있습니다. 상황을 이해하여 복잡한 자연어와 고객 문의에 대해 일관된 응답을 생성할 수 있습니다. 고객 지원, 가상 지원, 콘텐츠 생성에 있어서 탁월한 성능을 발휘하면서 개인화된 상호 작용을 제공합니다. 이러한 모델의 지속적인 학습 기능을 통해 시간이 지남에 따라 성능을 조정하고 개선하여 사용자 경험과 효율성을 향상시킬 수 있습니다.
일례로, 세계 최대 온라인 브로커 중 하나인 Deriv는 다양한 플랫폼에 분산된 방대한 양의 데이터에 액세스하는 데 어려움을 겪었습니다. 이 회사는 AI 기반 도우미를 구현하여 고객 지원, 마케팅, 채용 전반의 다양한 소스에서 데이터를 검색하고 처리했습니다. Deriv는 AI를 사용하여 신입 사원의 온보딩에 소요되는 시간을 45% 줄이고 채용 작업 시간을 50%로 최소화했습니다.

지능형 문서 처리
지능형 문서 처리(IDP)는 비정형 문서 형식을 사용 가능한 데이터로 변환합니다. 예를 들어 이메일, 이미지, PDF와 같은 비즈니스 문서를 구조화된 정보로 변환합니다. IDP는 자연어 처리(NLP), 딥 러닝, 컴퓨터 비전과 같은 AI 기술을 사용하여 데이터를 추출, 분류 및 검증합니다.
예를 들어 HM Land Registry(HMLR)는 87% 이상의 잉글랜드와 웨일즈 지역에 대한 부동산 소유권을 취급합니다. HMLR 사례 담당자는 부동산 거래와 관련된 복잡한 법률 문서를 비교하고 검토합니다. 이 조직은 AI 애플리케이션을 배포하여 문서 비교를 자동화함으로써 검토 시간을 50% 단축하고 부동산 양도의 승인 프로세스를 가속화했습니다. 자세히 알아보려면 HMLR이 Amazon Textract를 어떻게 사용하는지 읽어보세요.

애플리케이션 성능 모니터링
애플리케이션 성능 모니터링(APM)은 소프트웨어 도구와 원격 측정 데이터를 사용하여 비즈니스 크리티컬 애플리케이션의 성능을 모니터링하는 프로세스입니다. AI 기반 APM 도구는 기록 데이터를 사용하여 문제가 발생하기 전에 예측합니다. 또한 개발자에게 실질적인 솔루션을 제안하여 실시간으로 문제를 해결할 수 있습니다. 이 전략은 애플리케이션을 계속해서 효과적으로 실행하고 병목 현상을 해결합니다.
일례로 Atlassian은 팀워크와 조직을 간소화하는 제품을 만듭니다. Atlassian은 AI APM 도구를 사용하여 애플리케이션을 지속적으로 모니터링하고, 잠재적 문제를 탐지하며, 심각도의 우선 순위를 지정합니다. 이 기능을 통해 팀은 ML 기반 권장 사항에 신속하게 대응하고 성능 저하를 해결할 수 있습니다.

예측 유지 보수
AI 강화 예측 유지 보수란 대량의 데이터를 사용하여 운영, 시스템 또는 서비스의 가동 중지로 이어질 수 있는 문제를 식별하는 것을 말합니다. 기업에서는 예측 유지 보수를 통해 잠재적 문제를 발생 전에 해결하여 가동 중지 시간을 줄이고 중단을 예방할 수 있습니다.
예를 들어 Baxter는 전 세계 70개의 제조 공장을 운영하고 있으며 연중무휴 운영을 통해 의료 기술을 제공합니다. Baxter는 예측 유지 보수를 사용하여 산업 장비의 비정상 상태를 자동으로 감지합니다. 사용자는 효과적인 솔루션을 미리 구현하여 가동 중지 시간을 줄이고 운영 효율성을 개선할 수 있습니다. 자세히 알아보려면 Baxter가 Amazon Monitron을 사용하는 방법을 읽어보세요.

의학 연구
의학 연구에서는 AI를 사용하여 프로세스를 간소화하고, 반복적인 태스크를 자동화하며, 방대한 데이터를 처리합니다. 의학 연구에 AI 기술을 사용하면 신약 발견 및 개발의 전체 과정을 촉진하고, 의료 기록을 전사하며, 신제품 출시 시간을 단축할 수 있습니다.
실제 사례로 C2i Genomics는 인공 지능을 사용하여 사용자 지정 가능한 대규모 유전체 파이프라인과 임상 검사를 실행합니다. 연구원들은 컴퓨팅 솔루션을 다루면서 임상 성과 및 임상 수단 개발에 집중할 수 있습니다. 엔지니어링 팀 또한 AI를 사용하여 리소스 수요, 엔지니어링 유지 보수 및 NRE 비용을 줄일 수 있습니다. 자세히 알아보려면 C2i Genomics가 AWS HealthOmics를 사용하는 방법을 읽어보세요.

비즈니스용 인공 지능의 이점
조직은 인공 지능 기능을 통합하여 비즈니스 프로세스를 최적화하고 고객 경험을 개선하며 혁신을 가속화할 수 있습니다.
기계 학습, 딥 러닝, 인공 지능의 차이점은 무엇인가요?
인공 지능은 기계를 더 인간처럼 만들기 위한 다양한 전략과 기법을 포괄하는 용어입니다. AI에는 자율 주행 자동차부터 로봇 청소기와 Alexa 같은 스마트 도우미에 이르기까지 모든 것이 포함됩니다. 기계 학습과 딥 러닝은 AI 범주에 속하지만 모든 AI 활동이 기계 학습과 딥 러닝인 것은 아닙니다. 예를 들어 생성형 AI는 인간과 유사한 창의적 능력을 보여주며 매우 발전된 형태의 딥 러닝입니다.
기계 학습
인공 지능과 기계 학습이라는 용어가 여러 곳에서 혼용되는 것을 볼 수 있지만, 기계 학습은 엄밀히 말하면 인공 지능의 여러 분야 중 하나입니다. 데이터의 상관 관계를 파악하기 위한 알고리즘과 통계 모델을 개발하는 과학의 한 분야라고 할 수 있습니다. 컴퓨터 시스템은 기계 학습 알고리즘을 사용하여 대량의 기록 데이터를 처리하고 데이터 패턴을 식별합니다. 현재 기계 학습은 독립적으로 사용하거나 다른 복잡한 AI 기술을 지원하는 데 사용할 수 있는 기계 학습 모델이라는 일련의 통계 기법을 지칭하는 용어로 사용됩니다.
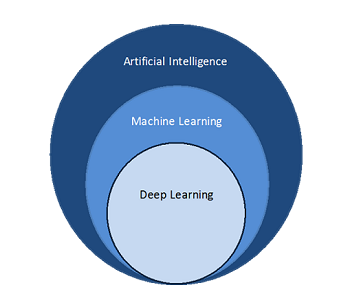
딥 러닝
딥 러닝은 기계 학습을 한 단계 더 발전시킨 개념입니다. 딥 러닝 모델은 함께 연동되는 신경망을 사용하여 정보를 학습하고 처리합니다. 이러한 모델은 더 큰 문제를 해결하기 위해 작은 데이터 단위에서 미시적 수학 연산을 수행하는 수백만 개의 소프트웨어 구성 요소로 구성됩니다. 예를 들어 이미지의 개별 픽셀을 처리하여 해당 이미지를 분류합니다. 최신 AI 시스템은 여러 심층 신경망을 결합하여 시를 쓰거나 텍스트 프롬프트를 바탕으로 이미지를 만드는 것과 같은 복잡한 작업을 수행합니다.
인공 지능은 어떻게 작동하나요?
인공 지능 시스템은 다양한 기술을 사용하여 작동합니다. 세부적인 방식은 서로 다르지만 핵심 원칙은 동일합니다. 즉, 텍스트, 이미지, 비디오, 오디오 등 모든 데이터 유형을 수치 표현으로 변환하고 이들 간의 패턴과 관계를 수학적으로 식별합니다. 따라서 인공 지능 기술에는 훈련이 필요합니다. 즉, 인공 지능은 인간이 기존 지식 아카이브에서 학습하는 것과 같은 방식으로 ‘학습’하기 위해 대량의 기존 데이터세트에 노출됩니다. 인공 지능의 기반이 되는 몇 가지 기술은 다음과 같습니다.
신경망
인공 지능 기술의 핵심은 인공 신경망입니다. 이 딥 러닝 신경망은 인간의 뇌에서 일어나는 처리 과정을 반영합니다. 뇌에는 정보를 처리하고 분석하는 수백만 개의 뉴런이 있습니다. 인공 신경망은 정보를 함께 처리하는 인공 뉴런을 사용합니다. 각 인공 뉴런 또는 노드는 수학적 계산을 사용하여 정보를 처리하고 복잡한 문제를 해결합니다.

자연어 처리
자연어 처리(NLP)는 신경망을 사용하여 텍스트 데이터에서 정보를 해석하고 이해하고 수집합니다. 인간의 언어를 해독하고 이해하는 데 특화된 다양한 컴퓨팅 기법을 사용합니다. 이러한 기법을 통해 머신이 단어, 문법 구문 및 단어 조합을 처리하여 인간의 텍스트를 처리하고 새로운 텍스트를 생성할 수 있습니다. 자연어 처리는 문서 요약, 챗봇, 감정 분석 수행을 수행하는 데 매우 중요합니다.

컴퓨터 비전
컴퓨터 비전은 딥 러닝 기법을 사용하여 비디오와 이미지에서 정보와 인사이트를 추출합니다. 컴퓨터 비전을 사용하여 온라인 콘텐츠에서 부적절한 이미지를 모니터링하고, 얼굴을 인식하고, 이미지 세부 정보를 분류할 수 있습니다. 자율 주행 자동차와 트럭에서는 환경을 모니터링하고 초를 가르는 결정을 내리는 것이 중요합니다.

음성 인식
음성 인식 소프트웨어는 딥 러닝 모델을 사용하여 사람의 음성을 해석하고 단어를 식별하며 의미를 감지합니다. 신경망은 음성을 텍스트로 전사하고 음성의 감정을 나타낼 수 있습니다. 가상 어시스턴트 및 고객 센터 소프트웨어와 같은 기술에서 음성 인식을 사용하여 의미를 식별하고 관련 태스크를 수행할 수 있습니다.

생성형 AI
생성형 AI는 간단한 텍스트 프롬프트에서 이미지, 비디오, 텍스트, 오디오와 같은 새로운 콘텐츠와 아티팩트를 생성하는 인공 지능 시스템을 말합니다. 데이터 분석에만 국한된 과거의 AI와 달리 생성형 AI는 딥 러닝과 대규모 데이터세트를 활용하여 인간과 유사한 높은 품질의 창의적 결과물을 생성합니다. 흥미로운 창의적 응용이 가능하지만 편향, 유해 콘텐츠 및 지적 재산에 대한 우려는 여전히 존재합니다. 전반적으로 생성형 AI는 인간과 유사한 방식으로 인간의 언어와 새로운 콘텐츠 및 아티팩트를 생성하는 AI 기능의 중대한 진화를 나타냅니다.

AI 애플리케이션 아키텍처의 주요 구성 요소는 무엇인가요?
인공 지능 아키텍처는 3개의 핵심 계층으로 구성됩니다. 모든 계층은 AI에 필요한 컴퓨팅 및 메모리 리소스를 제공하는 IT 인프라에서 실행됩니다.
초보자를 위한 AI 교육 옵션
AI 교육은 일반적으로 프로그래밍 및 컴퓨터 과학의 기초부터 시작합니다. 수학, 통계, 선형 대수와 함께 Python과 같은 언어를 배워야 합니다.
그런 다음 보다 전문적인 교육으로 넘어갈 수 있습니다. 인공 지능, 기계 학습 또는 데이터 과학 분야의 석사 학위를 취득하여 심층적인 이해와 실무 경험을 쌓으세요. 이러한 석사 학위 프로그램에는 일반적으로 신경망, 자연어 처리, 컴퓨터 비전 같은 심층적인 주제가 포함됩니다.
하지만 정규 교육 과정이 유일한 길은 아닙니다. 온라인 과정을 활용하여 원하는 속도로 학습하고 특정한 기술을 익힐 수 있습니다. 예를 들어, AWS 기반 생성형 AI 교육에는 다음과 같은 주제에 대한 AWS 전문가 자격증이 포함됩니다.
인공 지능 구현과 관련한 문제는 어떤 것들이 있나요?
AI의 구현과 사용을 복잡하게 만드는 몇 가지 문제가 있습니다. 다음은 가장 일반적인 문제 중 일부입니다.
AI 거버넌스
데이터 거버넌스 정책은 규제 제한 및 개인 정보 보호법을 준수해야 합니다. AI를 구현하려면 데이터 품질, 개인 정보 보호, 보안을 관리해야 합니다. 고객 데이터 및 개인 정보 보호에 대한 책임은 해당 조직에 있습니다. 데이터 보안을 관리하려면 각 계층에서 AI 모델이 고객 데이터를 어떻게 사용하고 상호 작용하는지 이해해야 합니다.

기술적 어려움
기계 학습으로 AI를 훈련하려면 막대한 리소스가 필요합니다. 딥 러닝 기술이 제대로 작동하려면 높은 처리 파워 임계값이 필수적입니다. AI 애플리케이션을 실행하고 모델을 훈련하려면 강력한 컴퓨팅 인프라가 있어야 합니다. 처리 파워는 비용이 높기 때문에 AI 시스템의 확장성을 제한할 수 있습니다.

책임 있는 AI
책임 있는 AI는 AI 시스템이 대규모로 미치는 사회적, 환경적 영향을 고려한 AI 개발 방식입니다. 모든 신기술이 그렇듯이, 인공 지능 시스템은 사용자, 사회 및 환경의 변화를 가져옵니다. 책임 있는 AI를 실현하려면 긍정적인 영향을 강화하고 AI 개발 및 사용 방식에 대한 공정성과 투명성을 우선으로 해야 합니다. 책임 있는 AI는 AI 혁신과 데이터 중심 의사 결정이 시민의 자유와 인권을 침해하지 않도록 막아줍니다. 조직들은 빠르게 발전하는 AI 분야에서 경쟁력을 유지하면서 책임 있는 AI를 구축하는 것이 쉽지 않음을 알게 됩니다.

데이터 제한
훈련을 통해 편향 없는 AI 시스템을 만들려면 방대한 양의 데이터를 입력해야 합니다. 훈련 데이터를 다루고 처리할 수 있는 충분한 스토리지 용량이 있어야 합니다. 마찬가지로 훈련에 사용하는 데이터의 정확성을 보장하기 위해 효과적인 관리 및 데이터 품질 프로세스를 마련해야 합니다.

AWS는 인공 지능 요구 사항을 어떻게 지원하나요?
AWS를 통해 빌더, 데이터 사이언티스트부터 비즈니스 분석가 및 학생에 이르기까지 더 많은 사람들이 AI에 액세스할 수 있습니다. AWS는 가장 포괄적인 AI 서비스, 도구 및 리소스 세트를 통해 10만 이상의 고객에게 심층적인 전문 지식을 제공하여 비즈니스 요구 사항을 충족하고 데이터의 가치를 극대화합니다. 고객은 개인 정보 보호, 엔드 투 엔드 보안, AI 거버넌스를 기반으로 한 AWS를 통해 구축하고 확장하여 전례 없는 속도로 혁신할 수 있습니다. AWS 기반 AI에는 바로 활용하여 성능을 극대화하고 비용을 절감할 수 있는 인텔리전스 및 AI 인프라를 위한 사전 훈련된 AI 서비스가 포함되어 있습니다.