“Burns Cliff”, “Colinas Columbia”, ”Endeavour” e “Cratera Bonneville” soam como coisa de outro mundo? Você está certo! Essas são algumas das estruturas geográficas visitadas pelas sondas de exploração de Marte (MER) da NASA. Com o decorrer dos anos, as sondas têm enviado coleções de dados excitantes incluindo imagens de alta resolução sobre o planeta vermelho. Agora, o Amazon SWF (Amazon Simple Workflow Service) reúne algumas das principais tecnologias de computação atrás dessas missões, habilitando os cientistas da NASA a conduzirem com confiança operações de missão crítica e a processarem eficientemente o conhecimento cada vez maior que obtemos sobre nosso universo.
Mars Exploration Rover
O Laboratório de Propulsão a Jato (JPL) da NASA usa o Amazon SWF como parte integral de várias missões, incluindo a Mars Exploration Rover (MER – sonda de exploração de Marte) e o CARVE (Carbon in the Arctic Reservoir Vulnerability Experiment). Essas missões geram continuamente grandes volumes de dados que devem ser processados, analisados e armazenados de modo eficiente e confiável. As pipelines de processamento de dados de operações táticas e análise científica envolvem execução de etapas ordenadas em grande escala com ampla oportunidade de paralelização entre várias máquinas. Os exemplos incluem a geração de dados estereoscópicos de pares de imagens, a emenda de vários panoramas gigapixel para mergulhar o cientista em terreno marciano, e a disposição lado a lado dessas imagens gigapixel de modo que os dados possam ser carregados on demand. Há uma comunidade global de operadores e cientistas que confiam em tais dados. Essa comunidade tem frequentemente um cronograma apertado para operações táticas, tão apertado quanto apenas algumas horas. Para atender a essas necessidades, os engenheiros do JPL estabeleceram um objetivo de processar e disseminar as imagens de Marte em minutos.
O JPL tem armazenado e processado dados na AWS. Muito desse trabalho é feito com a estrutura Polyphony, que é a implementação de referência da arquitetura orientada a nuvem do JPL. Ela fornece suporte para provisionamento, armazenamento, monitoramento e orquestração de tarefa dos trabalhos de processamento de dados na nuvem. O conjunto de ferramentas existente de Polyphony para processamento de dados e analítica era composto pelo Amazon EC2 para capacidade de computação, Amazon S3 para armazenamento e distribuição de dados, além das implementações do Amazon SQS e MapReduce, como o Hadoop, para distribuição de tarefas e execução. No entanto, faltava uma parte importante: um serviço de orquestração para gerenciar tarefas de modo confiável para fluxos de trabalho grandes e complexos.
Ao passo que as filas fornecem uma abordagem efetiva para distribuir massivamente trabalhos em paralelo, os engenheiros se deparavam rapidamente com as deficiências. A incapacidade de expressar a ordem e dependências dentro das filas as tornavam inadequadas para fluxos de trabalho complexos. Os engenheiros do JPL também tinham de lidar com a duplicação de mensagens ao usar as filas. Por exemplo, ao emendar imagens, uma tarefa duplicada para emendar uma imagem resultava em um processamento redundante dispendioso o que levava a computação dispendiosa adicional à medida que a pipeline avançava inutilmente para conclusão. O JPL também tem numerosos casos de uso que vão além do processamento bruto de dados e requerem mecanismos para conduzir o fluxo de controle. Ao passo que os engenheiros podiam implementar seus fluxos acionados por dados facilmente com o MapReduce, eles achavam difícil expressar cada etapa na pipeline dentro da semântica da estrutura. Especialmente, à medida que a complexidade do processamento de dados aumentava, eles enfrentavam dificuldades em representar as dependências entre as etapas de processamento e em manipular falhas de computação distribuídas.
Os engenheiros do JPL identificaram a necessidade de um serviço de orquestração com as seguintes características:
- Altamente disponível: para suportar operações de missão crítica
- Escalável: para facilitar a execução paralela simultaneamente de centenas de instâncias do Amazon EC2
- Consistente: uma tarefa planejada deve ser executada uma vez com probabilidade muito alta
- Expressivo: a expressão simples de fluxos de trabalho complexos para promover desenvolvimento
- Flexível: a execução de fluxos de trabalho não deve estar limitada ao Amazon EC2 e as tarefas devem ser roteáveis
- Eficiente: as tarefas devem ser planejadas com latência mínima
Os engenheiros do JPL usaram o Amazon SWF e integraram o serviço às pipelines Polyphony responsáveis pelo processamento de dados das imagens de Marte para operações táticas. Eles ganharam visibilidade e controle sem precedentes na execução distribuída de suas pipelines. O mais importante, eles podiam expressar fluxos de trabalho complexos de modo sucinto sem serem forçados a expressar o problema em qualquer paradigma específico.
Para dar suporte ao teste em campo de movimentação rápida da sonda Curiosity, também conhecido como Mars Science Laboratory (MSL – laboratório de ciência de Marte), os engenheiros do JPL tinham de processar imagens, gerar imagens estéreo e fazer panoramas. As imagens estéreo requerem um par de imagens adquiridas ao mesmo tempo, e geram um intervalo de dados que informa a um operador tático a distância e a direção da sonda aos pixels nas imagens. As imagens esquerda e direita podem ser processadas em paralelo; no entanto, o processamento estéreo não pode iniciar até que cada imagem tenha sido processada. Esse fluxo de trabalho “split-join” clássico é difícil de expressar com um sistema baseado em fila, ao passo que expressá-lo com o SWF requer algumas linhas simples do código Java junto com as anotações do AWS Flow Framework.


A geração de panoramas também é implementada como um fluxo de trabalho. Para fins táticos, os panoramas são gerados em cada local onde a sonda estaciona e tira fotos. Portanto, a qualquer momento que uma nova imagem chega de um local específico, o panorama é ampliado com as informações recentemente disponíveis. Devido à grande escala dos panoramas e a necessidade de gerá-los o mais rápido possível, o problema teve de ser dividido e orquestrado em numerosas máquinas. O algoritmo empregado pelos engenheiros divide o panorama em várias linhas grandes. A primeira tarefa do fluxo de trabalho é gerar cada uma das linhas com base nas imagens disponíveis no local. Uma vez geradas as linhas, elas são reduzidas a várias resoluções e dispostas lado a lado para serem consumidas por clientes remotos. Usando o conjunto complexo de recursos fornecido pelo Amazon SWF, os engenheiros do JPL expressaram esse fluxo de aplicativo como um fluxo de trabalho do Amazon SWF.
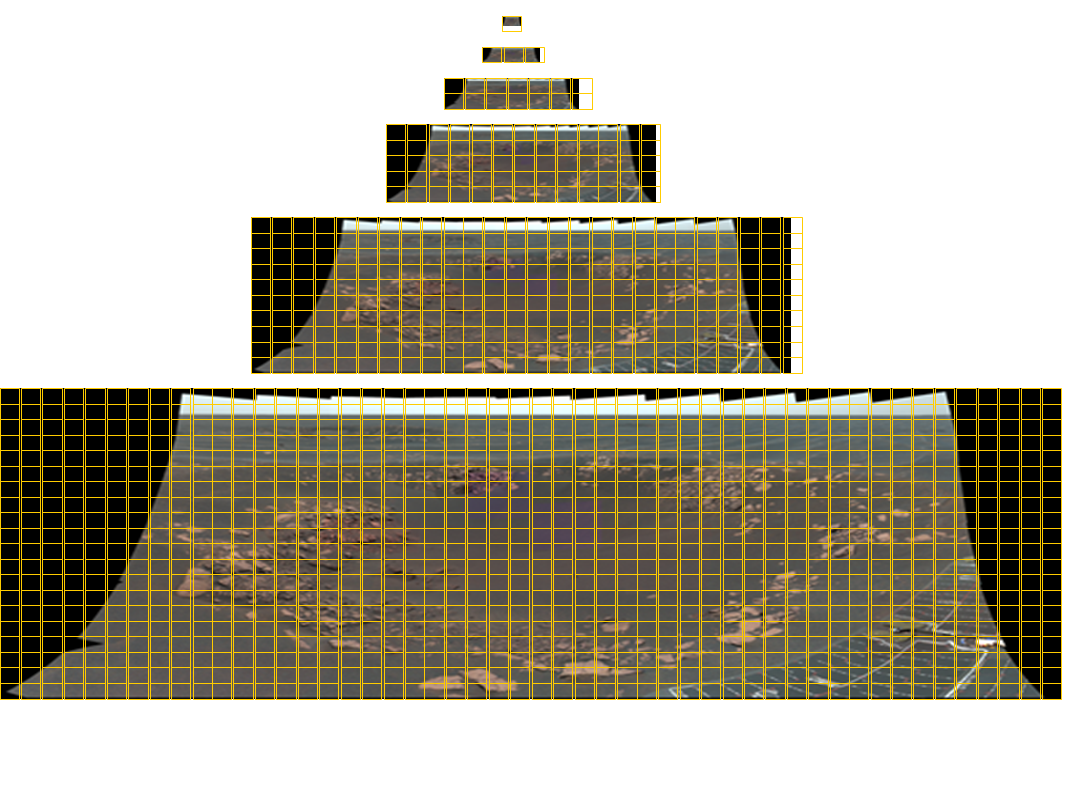
Um mosaico da Opportunity Pancam com tamanho total de 11.280×4.280 pixels contendo imagens de 77 cores. São necessários blocos em seis níveis de detalhes para distribuir essa imagem para um visualizador em qualquer tamanho arbitrário. As linhas de grade amarelas indicam os blocos necessários para cada imagem. O instrumento Panoramas for Mastcam no MSL é composto por até 1.296 imagens e tem uma resolução de quase 2 gigapixels. A imagem panorâmica correspondente é mostrada abaixo.

Ao disponibilizar a orquestração na nuvem, o Amazon SWF oferece ao JPL a capacidade de alavancar recursos dentro e fora de seu ambiente e distribuir automaticamente a execução do aplicativo na nuvem pública, permitindo que seus aplicativos sejam dinamicamente adaptados e executados de maneira realmente distribuída.
Muitas pipelines de processamento de dados do JPL estão estruturadas como trabalhadores automatizados para fazer upload dos dados em firewall, trabalhadores para processar os dados em paralelo e trabalhadores para fazer download dos resultados. Os trabalhadores de upload e download executam nos servidores locais e os trabalhadores de processamento de dados podem executar nos servidores locais e nos nós do Amazon EC2. Por usar os recursos de roteamento no Amazon SWF, os desenvolvedores do JPL incorporaram dinamicamente os operadores na pipeline enquanto tiram proveito das características do operador, por exemplo, a localidade dos dados. Esse aplicativo de processamento também é altamente disponível porque quando os trabalhadores locais falham, os trabalhadores baseados em nuvem continuam a levar o processamento para frente. Como o Amazon SWF não restringe a localização dos nós do operador, o JPL executa trabalhos em várias regiões além de em seus datacenters locais para levar em conta a maior disponibilidade de sistemas de missão crítica. À medida que o Amazon SWF torna-se disponível em várias regiões, o JPL planeja integrar o failover automático ao SWF entre regiões.

O uso do JPL do Amazon SWF não se limita aos aplicativos de processamento de dados. Usando os recursos de programação no Amazon SWF, os engenheiros do JPL criaram um sistema de trabalho distribuído, Cron, que executava com confiança, operações de missão crítica oportunamente. Além da confiabilidade, o JPL ganhou visibilidade centralizada, sem precedentes, nesses trabalhos distribuídos usando os recursos de visibilidade do Amazon SWF disponíveis no AWS Management Console. O JPL criou um aplicativo para backup dos dados essenciais da MER no Amazon S3. Com os trabalhos distribuídos do Cron, o JPL atualiza os backups e faz auditoria na integridade dos dados com a frequência desejada pelo projeto. Todas as etapas desse aplicativo incluindo criptografia, upload para o S3, seleção aleatória de dados para auditoria e auditoria real pela comparação dos dados no local com o S3 são orquestradas com confiança pelo Amazon SWF. Além disso, várias equipes do JPL migraram rapidamente seus aplicativos existentes para usar orquestração na nuvem, tirando proveito do suporte de programação fornecido pelo AWS Flow Framework.
O JPL continua a usar o Hadoop para pipelines de processamento de dados simples e o Amazon SWF é agora uma escolha natural para implementação de aplicativos com dependências complexas entre as etapas de processamento. Os desenvolvedores também usam frequentemente a capacidade de diagnóstico e analítica disponível usando o AWS Management Console para depurar aplicativos durante o desenvolvimento e acompanhamento das execuções distribuídas. Com a AWS, aplicativos de missão crítica que antes levavam vários meses para serem desenvolvidos, testados e implementados, agora levam apenas dias.