Amazon Bedrock Guardrails
Implementa misure di protezione personalizzate in base ai requisiti delle tue applicazioni e alle politiche di IA responsabile
Crea applicazioni di IA responsabile con Guardrails
Amazon Bedrock Guardrails offre protezioni configurabili per aiutare a creare in modo sicuro applicazioni di IA generativa su larga scala. Con un approccio coerente e standard utilizzato in un'ampia gamma di modelli di fondazione (FM), inclusi i modelli FM supportati in Amazon Bedrock, modelli ottimizzati con fine-tuning e modelli ospitati all'esterno di Amazon Bedrock, Guardrails offre protezioni di sicurezza leader del settore:
- Utilizza il ragionamento automatico per aiutare a prevenire gli errori fattuali dovuti alle allucinazioni ed è la prima e unica misura di protezione basata sull'IA generativa in grado di farlo
- Salvaguardia dei contenuti di testo e immagini leader del settore, che aiuta i clienti a bloccare fino all'88% dei contenuti multimodali dannosi
- Filtra oltre il 75% di risposte allucinate dai modelli per i casi d'uso di generazione potenziata tramite recupero (RAG) e riepilogo
Remitly trasforma l'assistenza clienti in modo rapido e affidabile utilizzando Amazon Bedrock
KONE potenzia l'assistenza sul campo basata sull'IA responsabile con Amazon Bedrock
Offri un livello costante di sicurezza nelle applicazioni di IA generativa
Guardrails è l'unica funzionalità di IA responsabile offerta da un importante fornitore di cloud che ti aiuta a creare e personalizzare le protezioni di sicurezza, privacy e veridicità per le tue applicazioni di IA generativa all'interno di un'unica soluzione. Guardrails consente di valutare gli input degli utenti e le risposte dei modelli in base a policy specifiche dei casi d'uso, fornendo un ulteriore livello di protezione oltre a quelli forniti nativamente dai FM. Guardrails funziona con un'ampia gamma di modelli, inclusi FM supportati in Amazon Bedrock, modelli ottimizzati e con hosting autonomo esterni ad Amazon Bedrock. Gli input degli utenti e gli output dei modelli possono essere valutati in modo indipendente per modelli di terzi e con hosting autonomo utilizzando l'API ApplyGuardrail. Guardrails può anche essere integrato con gli agenti Amazon Bedrock e le Knowledge Base di Amazon Bedrock per creare applicazioni di IA generativa più sicure in linea con le policy di IA responsabile.

Rileva le allucinazioni nelle risposte fornite dal modello utilizzando controlli di base contestuali
I clienti devono implementare applicazioni di IA generativa veritiere e affidabili per mantenere e accrescere la fiducia degli utenti. Tuttavia, gli FM possono generare informazioni errate a causa di allucinazioni, ad esempio deviando dall'informazione di origine, fondendo più informazioni o inventandone di nuove. Guardrails supporta controlli contestuali per contribuire a rilevare e filtrare le allucinazioni se le risposte non sono adeguate (ad esempio, informazioni nuove o di fatto inesatte) rispetto alle informazioni di origine e non sono pertinenti alla domanda o alle istruzioni immesse dall'utente. I controlli di base contestuali possono consentire di rilevare allucinazioni per applicazioni RAG, di riepilogo e di conversazione, in cui le informazioni di origine possono essere utilizzate come riferimento per convalidare la risposta del modello.

I controlli di ragionamento automatico aiutano a prevenire gli errori fattuali dovuti ad allucinazioni e offrono un'accuratezza verificabile
I controlli di ragionamento automatico (anteprima) in Amazon Bedrock Guardrails sono la prima e unica protezione di IA generativa che aiuta a prevenire errori di fatto dovuti ad allucinazioni utilizzando un ragionamento logicamente accurato e verificabile che spiega perché le risposte sono corrette. Il ragionamento automatico aiuta a mitigare le allucinazioni utilizzando solide tecniche matematiche per verificare, correggere e spiegare in modo logico le informazioni generate, assicurando che i risultati siano in linea con fatti noti e non siano basati su dati fabbricati o incoerenti. Gli sviluppatori possono creare una policy di ragionamento automatico caricando un documento esistente che definisce il giusto spazio di soluzione, ad esempio una linea guida per le risorse umane o un manuale operativo. Amazon Bedrock genera quindi una policy di ragionamento automatico univoca e guida gli utenti nel testarla e perfezionarla. Per convalidare i contenuti generati rispetto a una policy di ragionamento automatico, gli utenti devono abilitare la policy in Guardrails e configurarla con un elenco di nomi di risorse Amazon (ARN) univoci. Questo processo di verifica algoritmica basato sulla logica garantisce che le informazioni generate da un modello siano in linea con fatti noti e non si basino su dati fabbricati o incoerenti. Questi controlli forniscono risposte veritiere da parte di modelli di IA generativa, consentendo ai fornitori di software di migliorare l'affidabilità delle loro applicazioni per i casi d'uso in ambito HR, finanziario, legale, di conformità e altro ancora.

Blocca argomenti indesiderati nelle applicazioni di IA generativa
I leader delle organizzazioni riconoscono la necessità di gestire le interazioni all'interno delle applicazioni di IA generativa per un'esperienza utente pertinente e sicura. Desiderano personalizzare ulteriormente le interazioni, per rimanere concentrati su argomenti pertinenti alla loro attività e allinearsi alle policy aziendali. Utilizzando una breve descrizione in linguaggio naturale, Guardrails aiuta a definire una serie di argomenti da evitare nel contesto dell'applicazione. Guardrails contribuisce a rilevare e bloccare gli input dell'utente e le risposte dei FM che rientrano negli argomenti sottoposti a restrizioni. Ad esempio, un assistente bancario può essere progettato per evitare argomenti relativi alla consulenza in materia di investimenti.

Filtra i contenuti multimodali dannosi in base alle tue politiche di intelligenza artificiale responsabili
Guardrails fornisce filtri di contenuto con soglie configurabili per contenuti di testo e immagini inappropriati. La protezione aiuta a filtrare contenuti multimodali dannosi contenenti argomenti quali incitamento all'odio, insulti, sesso, violenza e cattiva condotta (compresa l'attività criminale) e aiuta a proteggere da attacchi dei prompt (iniezione di prompt e jailbreak). I filtri dei contenuti valutano automaticamente sia l'input dell'utente sia le risposte del modello per rilevare e aiutare a prevenire testo e immagini indesiderati e potenzialmente dannosi. Ad esempio, un sito di e-commerce può progettare il proprio assistente online per evitare l'uso di un linguaggio inappropriato, come incitamento all'odio o insulti.

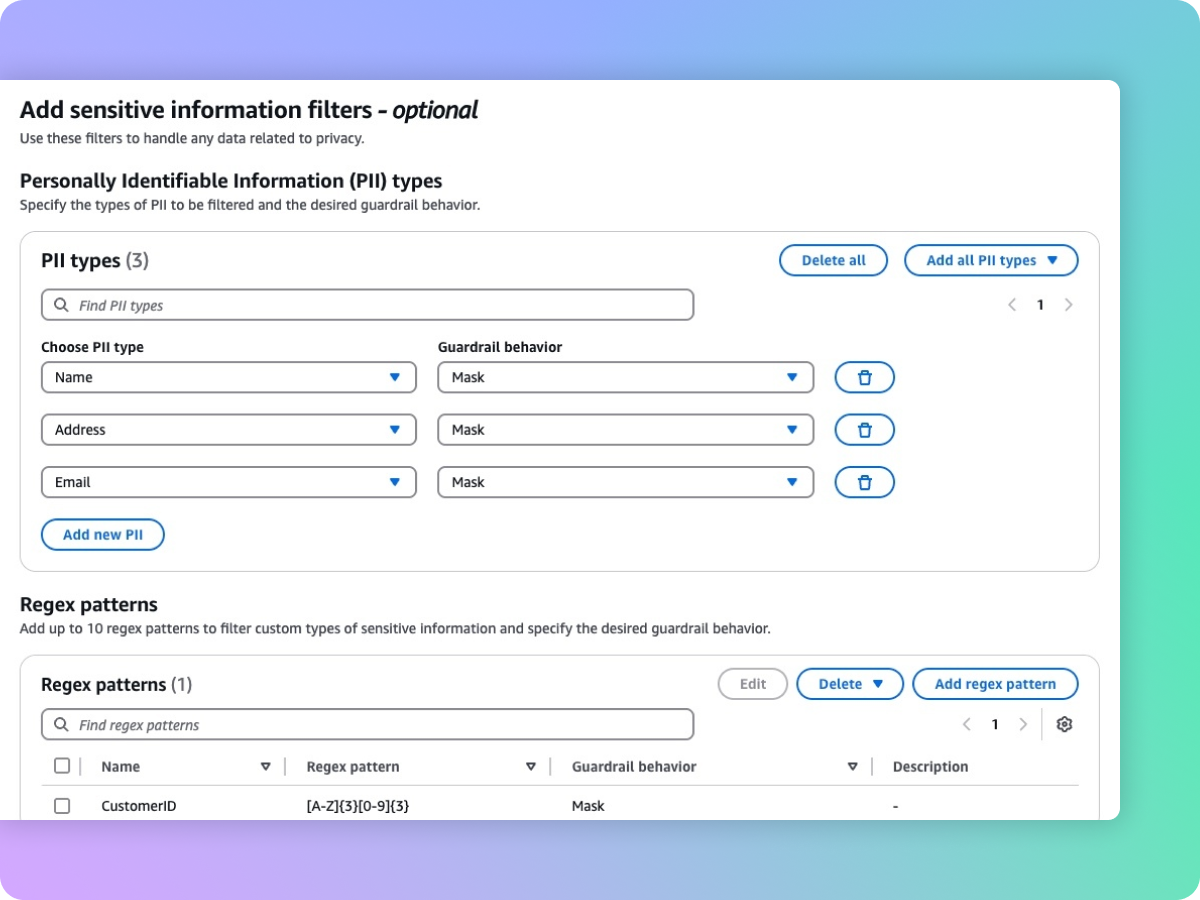
Redazione di informazioni sensibili, ad esempio le informazioni di identificazione personale (PII), per proteggere la privacy
Guardrails consente di rilevare contenuti sensibili, come le informazioni di identificazione personale (PII), all'interno degli input degli utenti e nelle risposte dei FM. È possibile selezionare da un elenco di Informazioni di identificazione personale (PII) o definire un tipo di informazioni sensibili personalizzato utilizzando espressioni regolari (RegEx). In base al caso d'uso, è possibile rifiutare selettivamente gli input contenenti PII oppure oscurare le PII nelle risposte FM. Ad esempio, puoi oscurare le informazioni personali degli utenti mentre generi riepiloghi delle trascrizioni delle conversazioni con clienti e agenti in un call center.
Fasi successive
Oggi hai trovato quello che cercavi?
Facci sapere la tua opinione in modo da poter migliorare la qualità dei contenuti delle nostre pagine.