



Apa itu pelabelan data?
Dalam machine learning, pelabelan data adalah proses mengidentifikasi data mentah (gambar, file teks, video, dll.) serta menambahkan satu atau beberapa label yang bermakna dan informatif untuk memberikan konteks agar model machine learning dapat belajar darinya. Misalnya, label mungkin menunjukkan apakah foto berisi burung atau mobil, kata-kata apa yang diucapkan dalam rekaman audio, atau apakah sinar-x berisi tumor. Pelabelan data diperlukan untuk berbagai kasus penggunaan termasuk penglihatan komputer, pemrosesan bahasa alami, dan pengenalan ucapan.
Bagaimana cara kerja pelabelan data?
Saat ini, sebagian besar machine learning praktis menggunakan pembelajaran yang diawasi, yang menerapkan algoritma untuk memetakan satu input ke satu output. Agar pembelajaran yang diawasi berfungsi, Anda memerlukan set data berlabel yang dapat dipelajari model untuk membuat keputusan yang benar. Pelabelan data biasanya dimulai dengan meminta manusia untuk membuat penilaian tentang sepotong data tanpa label tertentu. Misalnya, pemberi label mungkin diminta untuk menandai semua gambar dalam set data yang menyatakan “apakah ada burung di foto tersebut” adalah benar. Penandaan dapat berupa jawaban ya/tidak yang sederhana, atau terperinci, seperti mengidentifikasi piksel spesifik dalam gambar yang terkait dengan burung. Model machine learning menggunakan label yang disediakan manusia untuk mempelajari pola yang mendasarinya dalam proses yang disebut "pelatihan model." Hasilnya adalah model terlatih yang dapat digunakan untuk membuat prediksi pada data baru.
Dalam machine learning, set data yang dilabeli dengan benar yang Anda gunakan sebagai standar objektif untuk melatih dan menilai model tertentu sering disebut “ground truth.” Keakuratan model terlatih Anda akan tergantung pada keakuratan ground truth Anda sehingga sangat penting untuk mengalokasikan waktu dan sumber daya guna memastikan bahwa pelabelan data sangat akurat.
Apa saja tipe pelabelan data yang umum?
Penglihatan Komputer
Saat membangun sistem penglihatan komputer, pertama-tama Anda harus memberi label pada gambar, piksel, atau titik-titik utama, atau membuat batas yang sepenuhnya melingkupi gambar digital, yang dikenal sebagai kotak pembatas, untuk menghasilkan set data pelatihan Anda. Misalnya, Anda dapat mengklasifikasikan gambar berdasarkan tipe kualitas (seperti gambar produk vs. gaya hidup) atau konten (apa yang sebenarnya ada dalam gambar itu sendiri), atau Anda dapat mengelompokkan gambar pada tingkat piksel. Anda kemudian dapat menggunakan data pelatihan ini untuk membangun model penglihatan komputer yang dapat digunakan untuk secara otomatis mengategorikan gambar, mendeteksi lokasi objek, mengidentifikasi titik-titik utama dalam gambar, atau mengelompokkan gambar.
Pemrosesan Bahasa Alami
Pemrosesan bahasa alami mengharuskan Anda untuk terlebih dahulu mengidentifikasi bagian penting dari teks secara manual atau menandai teks dengan label tertentu untuk menghasilkan set data pelatihan Anda. Misalnya, Anda mungkin ingin mengidentifikasi sentimen atau maksud dari teks promosi, mengidentifikasi kelas kata, mengklasifikasikan kata benda yang tepat, seperti tempat dan orang, serta mengidentifikasi teks dalam gambar, PDF, atau file lainnya. Untuk melakukan hal ini, Anda dapat menggambar kotak pembatas di sekitar teks lalu menyalin teks secara manual dalam set data pelatihan Anda. Model pemrosesan bahasa alami digunakan untuk analisis sentimen, pengenalan nama entitas, dan pengenalan karakter optik.
Pemrosesan Audio
Pemrosesan audio mengonversi semua jenis suara seperti ucapan, suara satwa liar (gonggongan, siulan, atau kicauan), dan suara bangunan (pecahan kaca, pemindaian, atau alarm) ke dalam format terstruktur sehingga dapat digunakan dalam machine learning. Pemrosesan audio sering mengharuskan Anda untuk terlebih dahulu menyalinnya secara manual ke dalam teks tertulis. Dari sana, Anda dapat mengungkap informasi yang lebih dalam mengenai audio dengan menambahkan tanda dan mengategorikan audio. Audio yang dikategorikan ini menjadi set data pelatihan Anda.
Apa saja praktik terbaik untuk pelabelan data?
Ada banyak teknik untuk meningkatkan efisiensi dan akurasi pelabelan data. Beberapa teknik ini meliputi:
- Antarmuka tugas yang intuitif dan efisien untuk membantu meminimalkan beban kognitif dan peralihan konteks untuk pemberi label manusia.
- Konsensus pemberi label untuk membantu menangkal kesalahan/bias dari masing-masing anotator. Konsensus pemberi label melibatkan pengiriman setiap objek set data ke beberapa anotator lalu mengonsolidasikan respons mereka (disebut “anotasi”) ke dalam satu label.
- Audit label untuk memverifikasi keakuratan label dan memperbaruinya jika diperlukan.
- Pembelajaran aktif untuk menjadikan pelabelan data lebih efisien menggunakan machine learning guna mengidentifikasi data yang paling bermanfaat untuk dilabeli oleh manusia.
Bagaimana pelabelan data dapat dilakukan secara efisien?
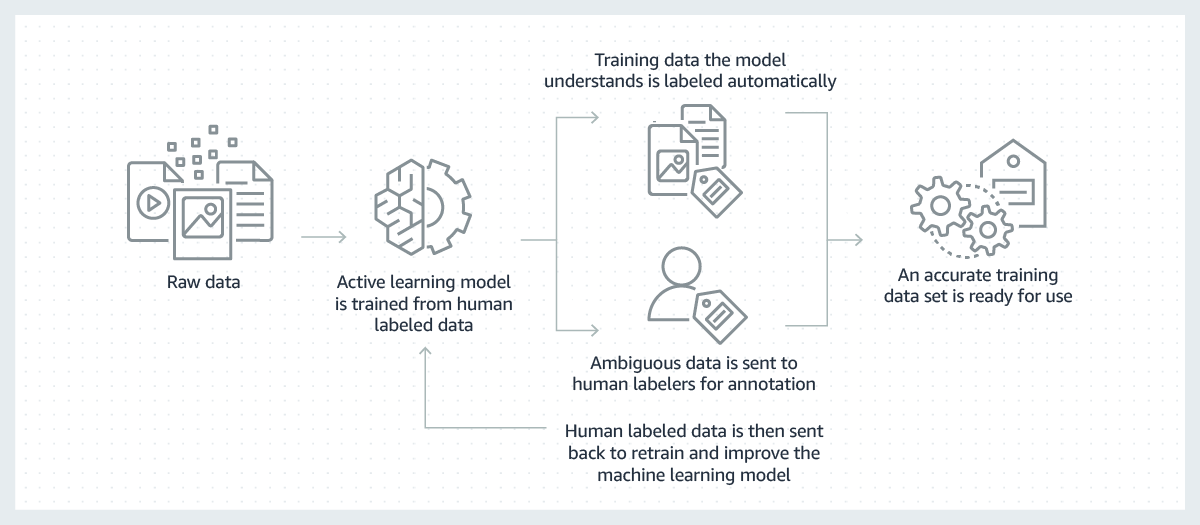
Model machine learning yang sukses dibangun dari data pelatihan berkualitas tinggi volume besar. Tetapi, proses untuk membuat data pelatihan yang diperlukan untuk membangun model tersebut seringkali mahal, rumit, dan memakan waktu. Mayoritas model yang dibuat saat ini mengharuskan manusia untuk melabeli data secara manual sehingga model dapat mempelajari cara membuat keputusan yang benar. Untuk mengatasi tantangan ini, pelabelan dapat dibuat lebih efisien menggunakan model machine learning untuk melabeli data secara otomatis.
Dalam proses ini, model machine learning untuk pelabelan data pertama-tama dilatih pada subset data mentah Anda yang telah dilabeli oleh manusia. Jika model pelabelan memiliki keyakinan yang tinggi terhadap hasilnya berdasarkan apa yang telah dipelajari sejauh ini, model tersebut akan secara otomatis menerapkan label pada data mentah. Jika model pelabelan memiliki keyakinan yang lebih rendah terhadap hasilnya, model tersebut akan meneruskan datanya ke manusia untuk melakukan pelabelan. Label yang dibuat oleh manusia kemudian diberikan kembali ke model pelabelan agar dapat dipelajari dan meningkatkan kemampuannya dalam melabeli set data mentah berikutnya secara otomatis. Seiring waktu, model tersebut dapat melabeli lebih banyak data secara otomatis dan secara substansial mempercepat pembuatan set data pelatihan.
Bagaimana AWS dapat mendukung persyaratan pelabelan data Anda?
Amazon SageMaker Ground Truth secara signifikan mengurangi waktu dan upaya yang diperlukan untuk membuat set data untuk pelatihan. SageMaker Ground Truth menawarkan akses ke pemberi label manusia publik dan privat serta memberi mereka alur kerja dan antarmuka bawaan untuk tugas pelabelan umum. Sangat mudah untuk memulai SageMaker Ground Truth. Tutorial Memulai dapat digunakan untuk membuat tugas pelabelan pertama Anda dalam hitungan menit.
Mulai Pelabelan Data di AWS dengan membuat akun sekarang juga.