



Apa itu boosting dalam machine learning?
Boosting adalah metode yang digunakan dalam machine learning untuk mengurangi kesalahan dalam analisis data prediktif. Ilmuwan data melatih perangkat lunak machine learning, yang disebut model machine learning, pada data berlabel untuk menebak data yang tidak berlabel. Model machine learning tunggal dapat membuat kesalahan prediksi tergantung pada akurasi dari set data pelatihan. Misalnya, jika model pengidentifikasi kucing telah dilatih hanya pada citra kucing putih, terkadang model tersebut salah mengidentifikasi kucing hitam. Boosting mencoba mengatasi masalah ini dengan melatih beberapa model secara berurutan untuk meningkatkan akurasi sistem secara keseluruhan.
Mengapa boosting penting?
Boosting meningkatkan akurasi dan performa prediktif model mesin dengan mengubah beberapa pembelajar lemah menjadi satu model pembelajaran kuat. Model machine learning dapat berupa pembelajar yang lemah atau pembelajar yang kuat:
Pembelajar lemah
Pembelajar lemah memiliki akurasi prediksi yang rendah, hampir sama dengan tebakan acak. Pembelajar lemah rentan terhadap overfitting—yaitu, tidak dapat mengklasifikasikan data yang terlalu berbeda dengan set data aslinya. Misalnya, jika Anda melatih model untuk mengidentifikasi kucing sebagai hewan dengan telinga runcing, model tersebut mungkin gagal mengenali kucing yang telinganya melengkung.
Pembelajar kuat
Pembelajar kuat memiliki akurasi prediksi yang lebih tinggi. Boosting mengubah sistem pembelajar lemah menjadi satu sistem pembelajaran kuat. Misalnya, untuk mengidentifikasi citra kucing, pembelajar kuat menggabungkan pembelajar lemah yang menebak telinga runcing dan pembelajar lain yang menebak bentuk mata kucing. Setelah menganalisis citra hewan bertelinga runcing, sistem tersebut menganalisisnya sekali lagi untuk bentuk mata kucing. Analisis ini meningkatkan akurasi sistem secara keseluruhan.
Bagaimana cara kerja boosting?
Untuk memahami cara kerja boosting, mari kita gambarkan cara model machine learning membuat keputusan. Meskipun ada banyak variasi dalam implementasinya, ilmuwan data sering menggunakan boosting dengan algoritme pohon keputusan:
Pohon keputusan
Pohon keputusan adalah struktur data dalam machine learning yang bekerja dengan membagi set data menjadi lebih kecil dan subset yang lebih kecil berdasarkan fiturnya. Idenya adalah bahwa pohon keputusan membagi data berulang kali hingga hanya ada satu kelas yang tersisa. Misalnya, pohon dapat mengajukan serangkaian pertanyaan ya atau tidak dan membagi data ke dalam kategori di setiap langkah.
Metode ansambel boosting
Boosting membuat model ansambel dengan menggabungkan beberapa pohon keputusan yang lemah secara berurutan. Penggabungan ini menetapkan bobot pada output masing-masing pohon. Kemudian memberikan klasifikasi yang salah dari pohon keputusan pertama dengan bobot yang lebih tinggi dan input ke pohon berikutnya. Setelah banyak siklus, metode boosting menggabungkan aturan lemah ini menjadi satu aturan prediksi yang kuat.
Membandingkan boosting dengan bagging
Boosting dan bagging adalah dua metode ensambel umum yang meningkatkan akurasi prediksi. Perbedaan utama di antara metode pembelajaran ini adalah metode pelatihan. Dalam bagging, ilmuwan data meningkatkan akurasi pembelajar lemah dengan melatih beberapa pembelajar sekaligus pada beberapa set data. Sebaliknya, boosting melatih pembelajar lemah satu per satu.
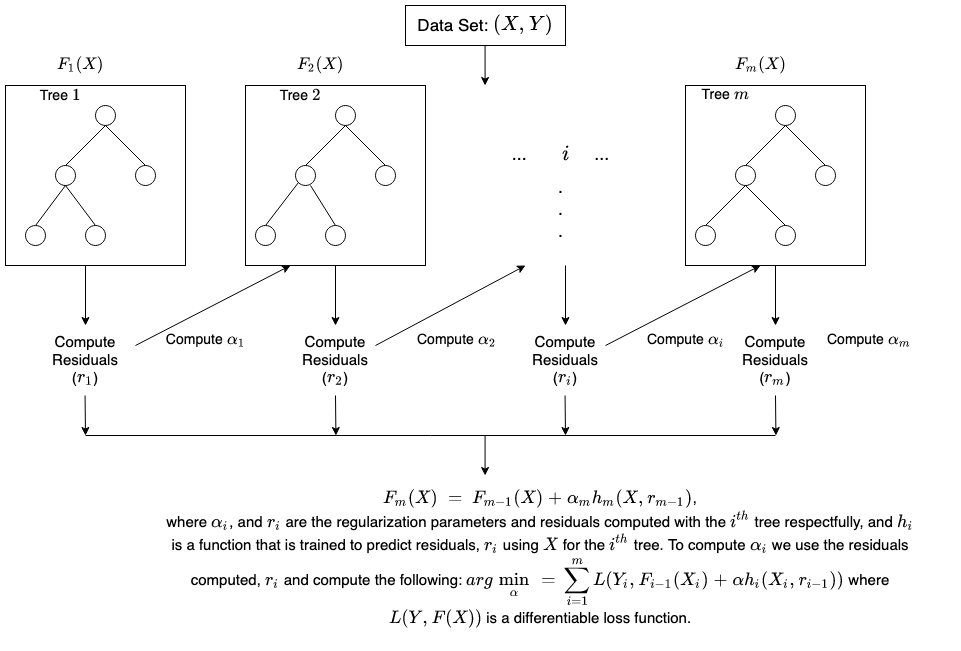
Bagaimana cara melakukan pelatihan dalam boosting?
Metode pelatihan bervariasi tergantung pada tipe proses boosting yang disebut algoritme boosting. Namun, algoritme mengambil langkah-langkah umum berikut untuk melatih model boosting:
Langkah 1
Algoritme boosting menetapkan bobot yang sama untuk setiap sampel data. Algoritme ini memasukkan data ke model mesin pertama, yang disebut algoritme dasar. Algoritme dasar membuat prediksi untuk setiap sampel data.
Langkah 2
Algoritme boosting menilai prediksi model dan meningkatkan bobot sampel dengan kesalahan yang lebih signifikan. Algoritme ini juga menetapkan bobot berdasarkan performa model. Model yang menghasilkan prediksi yang sangat baik akan memiliki pengaruh yang tinggi terhadap keputusan akhir.
Langkah 3
Algoritme tersebut meneruskan data berbobot ke pohon keputusan berikutnya.
Langkah 4
Algoritme tersebut mengulangi langkah 2 dan 3 hingga instans kesalahan pelatihan berada di bawah ambang batas tertentu.
Apa saja tipe-tipe boosting?
Berikut ini adalah tiga tipe utama dari boosting:
Boosting adaptif
Boosting Adaptif (AdaBoost) adalah salah satu model boosting yang dikembangkan paling awal. Boosting Adaptif menyesuaikan dan mencoba mengoreksi secara mandiri di setiap iterasi proses boosting.
AdaBoost awalnya memberikan bobot yang sama untuk setiap set data. Kemudian, secara otomatis menyesuaikan bobot titik data setelah setiap pohon keputusan. AdaBoost memberikan bobot lebih pada item dengan klasifikasi yang salah agar diperbaiki di putaran berikutnya. AdaBoost mengulangi proses tersebut hingga kesalahan yang tersisa, atau selisih antara nilai aktual dan prediksi, jatuh di bawah ambang batas yang dapat diterima.
Anda dapat menggunakan AdaBoost dengan banyak prediktor, dan biasanya tidak sesensitif algoritme boosting lainnya. Pendekatan ini tidak berfungsi dengan baik ketika ada korelasi antara fitur atau dimensi data yang tinggi. Secara keseluruhan, AdaBoost adalah tipe boosting yang cocok untuk masalah klasifikasi.
Boosting gradien
Boosting Gradien (GB) mirip dengan AdaBoost karena juga merupakan teknik pelatihan yang berurutan. Perbedaan antara AdaBoost dan GB adalah GB tidak memberikan bobot lebih pada item dengan klasifikasi yang salah. Sebagai gantinya, perangkat lunak GB mengoptimalkan fungsi kehilangan dengan menghasilkan pembelajar dasar secara berurutan sehingga pembelajar dasar saat ini selalu lebih efektif dibandingkan sebelumnya. Awalnya metode ini mencoba untuk mengeluarkan hasil yang akurat, alih-alih mengoreksi kesalahan di sepanjang proses, seperti AdaBoost. Untuk alasan ini, perangkat lunak GB dapat memberikan hasil yang lebih akurat. Boosting Gradien dapat membantu kedua permasalahan, baik yang berbasis klasifikasi maupun regresi.
Boosting gradien ekstrem
Boosting Gradien Ekstrem (XGBoost) meningkatkan kecepatan dan skala komputasi pada boosting gradien dengan beberapa cara. XGBoost menggunakan beberapa inti pada CPU sehingga pembelajaran dapat terjadi secara paralel selama pelatihan. XGBoost adalah algoritme boosting yang dapat menangani set data yang luas, membuatnya atraktif untuk aplikasi big data. Fitur utama XGBoost adalah paralelisasi, komputasi terdistribusi, optimisasi cache, dan pemrosesan di luar inti.
Apa saja manfaat boosting?
Boosting menawarkan manfaat utama berikut:
Kemudahan implementasi
Boosting memiliki algoritme yang mudah dipahami dan mudah ditafsirkan yang belajar dari kesalahannya. Algoritme ini tidak memerlukan pra-pemrosesan data apa pun, dan memiliki rutinitas bawaan untuk menangani data yang hilang. Selain itu, sebagian besar bahasa memiliki pustaka bawaan untuk mengimplementasikan algoritme boosting dengan banyak parameter yang dapat menyempurnakan performa.
Pengurangan bias
Bias adalah adanya ketidakpastian atau ketidakakuratan dalam hasil machine learning. Algoritme boosting menggabungkan beberapa pembelajar lemah dalam metode berurutan, yang secara iteratif meningkatkan pengamatan. Pendekatan ini membantu mengurangi bias tinggi yang umum terjadi pada model machine learning.
Efisiensi komputasional
Algoritme boosting memprioritaskan fitur yang meningkatkan akurasi prediktif selama pelatihan. Algoritme boosting dapat membantu mengurangi atribut data dan menangani set data besar secara efisien.
Apa tantangan untuk boosting?
Berikut ini adalah batasan umum mode boosting:
Kelemahan terhadap data outlier
Model boosting rentan terhadap outlier atau nilai data yang berbeda dari set data lainnya. Karena setiap model mencoba untuk memperbaiki kesalahan pendahulunya, outlier dapat mengubah hasil secara signifikan.
Implementasi waktu nyata
Anda mungkin juga merasa kesulitan menggunakan boosting untuk implementasi waktu nyata karena algoritmenya lebih kompleks dibandingkan proses lainnya. Metode boosting memiliki kemampuan beradaptasi yang tinggi, sehingga Anda dapat menggunakan berbagai macam parameter model yang langsung memengaruhi performa model.
Bagaimana AWS dapat membantu Anda melakukan boosting?
Layanan jaringan AWS dirancang untuk menyediakan beberapa hal berikut ini bagi korporasi:
Amazon SageMaker
Amazon SageMaker menyatukan serangkaian kemampuan yang dibuat khusus untuk machine learning. Anda dapat menggunakannya untuk mempersiapkan, membangun, melatih, dan melakukan deployment pada model machine learning berkualitas tinggi dengan cepat.
Amazon SageMaker Canvas
Amazon SageMaker Canvas menghilangkan pekerjaan berat saat membangun model machine learning serta membantu Anda membangun dan melatih model secara otomatis berdasarkan data Anda. Dengan SageMaker Canvas, Anda menyediakan set data tabular dan memilih kolom target untuk diprediksi, yang dapat berupa angka atau kategori. SageMaker Autopilot akan secara otomatis menjelajahi berbagai solusi untuk menemukan model yang terbaik. Anda kemudian dapat langsung melakukan deployment pada model ke produksi dengan sekali klik, atau mengulangi solusi yang disarankan dengan menggunakan Amazon SageMaker Studio agar kualitas model lebih ditingkatkan.
Amazon SageMaker Model Training
Pelatihan Model Amazon SageMaker memudahkan pengoptimalan model machine learning dengan mengambil metrik pelatihan secara waktu nyata dan mengirimkan pemberitahuan saat layanan mendeteksi kesalahan. Proses ini langsung membantu Anda memperbaiki prediksi model yang tidak akurat, seperti identifikasi citra yang salah.
Amazon SageMaker menawarkan metode yang cepat dan mudah untuk melatih model dan set data deep learning yang besar. Pustaka pelatihan yang didistribusikan SageMaker melatih set data besar lebih cepat.
Mulai Amazon SageMaker dengan membuat akun AWS sekarang juga.