Barrières de protection Amazon Bedrock
Mettez en œuvre des mesures de protection adaptées aux exigences de votre application et à des politiques d'IA responsables
Création d’applications d’IA responsables à l’aide des garde-fous
Les garde-fous Amazon Bedrock fournissent des garanties configurables pour aider à créer en toute sécurité des applications d’IA génératives à mise à l’échelle. Grâce à une approche cohérente et standard utilisée sur un large éventail de modèles de fondation (FM), y compris les FM pris en charge dans Amazon Bedrock, les modèles ajustés et les modèles hébergés en dehors d’Amazon Bedrock, les barrières de protection fournissent des protections de sécurité de pointe :
- Utilise le raisonnement automatisé pour aider à prévenir les erreurs factuelles dues aux hallucinations, la première et la seule protection d’IA générative à le faire
- Des mesures de protection du contenu au format texte ou image de pointe, qui aident les clients à bloquer jusqu’à 88 % des contenus multimodaux préjudiciables
- Filtre plus de 75 % des réponses hallucinées provenant de modèles pour les cas d’utilisation de génération à enrichissement contextuel (RAG) et de synthèse
Remitly transforme le support client avec rapidité et confiance grâce à Amazon Bedrock
KONE alimente un service d’IA responsable sur le terrain grâce à Amazon Bedrock
Garantir un niveau de sécurité constant pour toutes les applications d’IA génératives
Les garde-fous représentent la seule fonctionnalité d’IA responsable proposée par un important fournisseur de cloud qui vous aide à créer et à personnaliser des garanties de sécurité, de confidentialité et de conformité pour vos applications d’IA génératives au sein d’une solution unique. Les garde-fous aident à évaluer les entrées des utilisateurs et les réponses des modèles sur la base de politiques spécifiques à chaque cas d’utilisation et fournissent une couche supplémentaire de sauvegardes en plus de celles fournies nativement par les FM. Les garde-fous fonctionnent avec un large éventail de modèles, notamment des machines virtuelles prises en charge dans Amazon Bedrock, des modèles optimisés et des modèles auto-hébergés en dehors d’Amazon Bedrock. Les entrées utilisateur et les sorties de modèles peuvent être évaluées indépendamment pour les modèles tiers et auto-hébergés à l’aide de l’API ApplyGuardRail. Les garde-fous peuvent également être intégrés aux agents et aux bases de connaissances Amazon Bedrock afin de créer des applications d’IA générative conformes à vos politiques d’IA responsable.

Détection des hallucinations dans les réponses des modèles à l’aide de vérifications contextuelles
Les clients doivent déployer des applications d’IA générative conformes à la réalité et dignes de confiance afin de maintenir et d’accroître la confiance des utilisateurs. Cependant, les FM peuvent générer des informations incorrectes en raison d’hallucinations, c’est-à-dire en s’écartant de l’information source, en mélangeant plusieurs informations ou en inventant de nouvelles informations. Les barrières de protection Amazon Bedrock prennent en charge les contrôles contextuels d’ancrage pour aider à détecter et à filtrer les hallucinations si les réponses ne sont pas ancrées (par exemple, inexactitude des faits ou nouvelles informations) dans les informations sources et ne sont pas pertinentes par rapport à la requête ou à l’instruction de l’utilisateur. Les contrôles d’ancrage contextuel peuvent aider à détecter les hallucinations pour les applications de RAG, de résumé et de conversation, où l’information source peut être utilisée comme référence pour valider la réponse du modèle.

Les contrôles de raisonnement automatisés aident à prévenir les erreurs factuelles dues aux hallucinations et offrent une précision vérifiable
Les vérifications de raisonnement automatisé (version préliminaire) des garde-fous Amazon Bedrock constituent la première et la seule protection d’IA générative qui permettent de prévenir les erreurs factuelles liées aux hallucinations en utilisant un raisonnement logiquement précis et vérifiable expliquant pourquoi les réponses sont correctes. Le raisonnement automatisé permet d’atténuer les hallucinations en utilisant des techniques mathématiques solides pour vérifier, corriger et expliquer logiquement les informations générées, garantissant ainsi que les résultats correspondent à des faits connus et ne sont pas basés sur des données fabriquées ou incohérentes. Les développeurs peuvent créer une politique de raisonnement automatisé en téléchargeant un document existant qui définit l’espace de solution approprié, tel qu’une directive RH ou un manuel opérationnel. Amazon Bedrock génère ensuite une politique de raisonnement automatisé unique et guide les utilisateurs pour la tester et l’affiner. Pour valider le contenu généré par rapport à une politique de raisonnement automatisé, les utilisateurs doivent activer la politique dans les garde-fous et la configurer avec une liste Amazon Resource Name (ARN) uniques. Ce processus de vérification algorithmique basé sur la logique garantit la conformité des informations générées par un modèle avec les faits connus et ne repose pas sur des données fabriquées ou incohérentes. Ces contrôles fournissent des réponses dont la conformité est prouvée par des modèles d’IA générative, permettant aux fournisseurs de logiciels d’améliorer la fiabilité de leurs applications pour les cas d’utilisation dans les domaines des ressources humaines, de la finance, du droit, de la conformité, et bien plus encore.

Bloquez les sujets indésirables dans les applications d’IA génératives
Les dirigeants d’organisations reconnaissent la nécessité de gérer les interactions au sein des applications d’IA générative pour une expérience utilisateur pertinente et sûre. Ils souhaitent personnaliser davantage les interactions pour qu’elles restent centrées sur des sujets en rapport avec leur activité et qu’elles soient conformes aux politiques de l’entreprise. À l’aide d’une courte description en langage naturel, la méthode de garde-fous vous aide à définir un ensemble de sujets à éviter dans le contexte de votre application. Les garde-fous permettent de détecter et bloquer les entrées des utilisateurs et les réponses des FM qui relèvent des sujets restreints. Par exemple, un assistant bancaire peut être conçu pour éviter les sujets liés aux conseils en investissement.

Filtrez les contenus multimodaux nuisibles en fonction de vos politiques d’IA responsable
Guardrails fournit des filtres de contenu avec des seuils configurables pour les contenus textuels et images toxiques. Cette protection permet de filtrer les contenus multimodaux préjudiciables contenant des sujets tels que des discours de haine, des insultes, de la sexualité, de la violence et des mauvaises conduites (y compris des activités criminelles) et de protéger contre les attaques par invite (par injection d’invites et jailbreak). Les filtres de contenu évaluent automatiquement les entrées des utilisateurs et les réponses des modèles afin de détecter et de prévenir les contenus au format texte et/ou image indésirables et potentiellement dangereux. Par exemple, un site d'e-commerce peut concevoir son assistant en ligne de manière à éviter d'utiliser un langage inapproprié tel que des paroles haineuses ou des insultes.

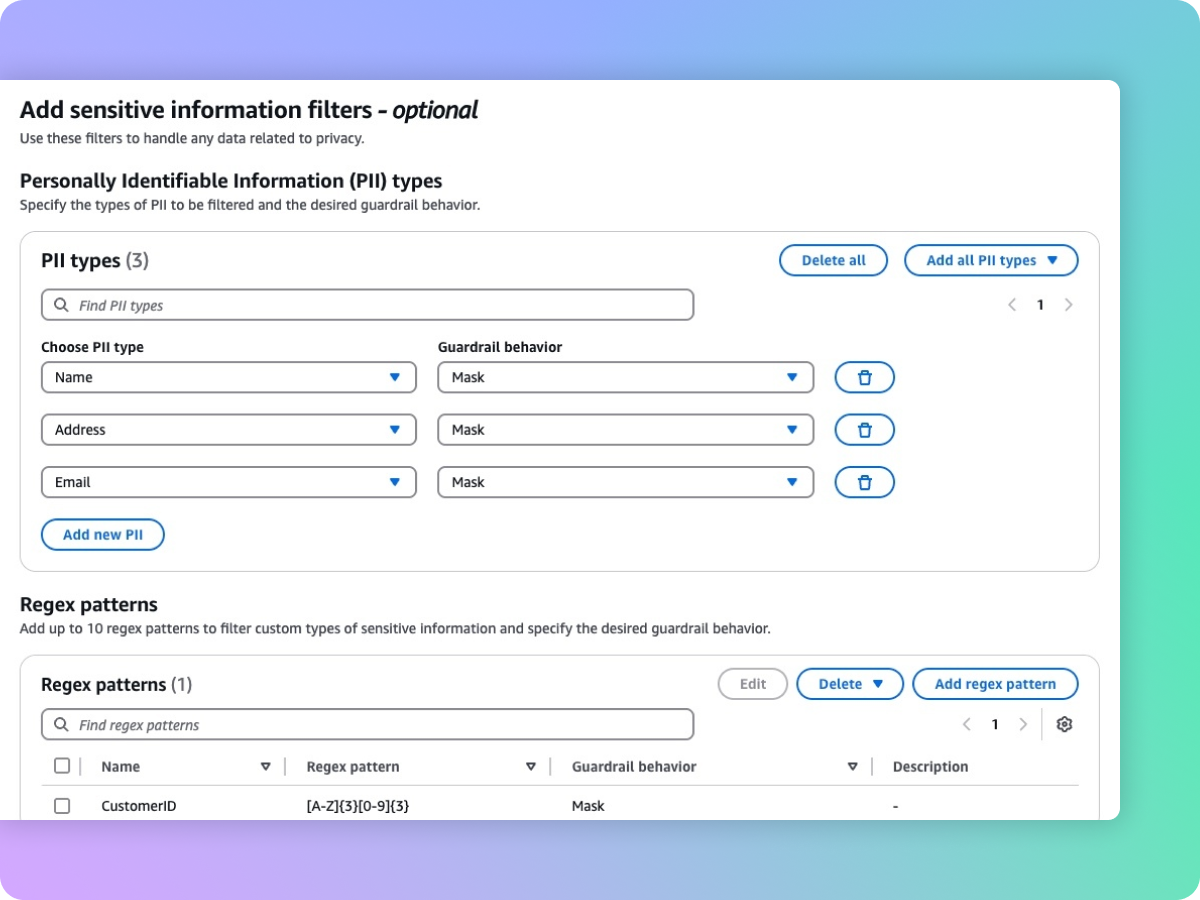
Supprimer les informations sensibles telles que les PII pour protéger la vie privée
Les garde-fous vous aident à détecter les contenus sensibles tels que les données d’identification personnelles (PII) dans les entrées utilisateur et les réponses FM. Vous pouvez sélectionner une liste de PII prédéfinies ou définir un type d’information sensible personnalisé à l’aide d’expressions régulières (RegEx). Selon le cas d’utilisation, vous pouvez rejeter de manière sélective les entrées contenant des informations sensibles ou les supprimer dans les réponses des FM. Par exemple, vous pouvez supprimer les informations personnelles des utilisateurs tout en générant des résumés à partir des transcriptions des conversations entre les clients et les agents dans un centre d'appels.
Étapes suivantes
Avez-vous trouvé ce que vous recherchiez aujourd’hui ?
Faites-le nous savoir afin que nous puissions améliorer la qualité du contenu de nos pages.