Amazon SageMaker Data Wrangler
La manera más rápida y sencilla de preparar datos para machine learning ahora se encuentra en SageMaker Canvas
¿Por qué SageMaker Data Wrangler?
Amazon SageMaker Data Wrangler reduce el tiempo de preparación de datos tabulares, de imágenes y de texto de semanas a minutos. Con SageMaker Data Wrangler, puede simplificar la preparación de datos y la ingeniería de características mediante una interfaz visual y de lenguaje natural. Seleccione, importe y transforme datos rápidamente con SQL y más de 300 transformaciones integradas sin necesidad de escribir código. Genere informes intuitivos sobre la calidad de los datos para detectar anomalías en todos los tipos de datos y estimar el rendimiento del modelo. Escale para procesar petabytes de datos.
Beneficios de SageMaker Data Wrangler
Funcionamiento
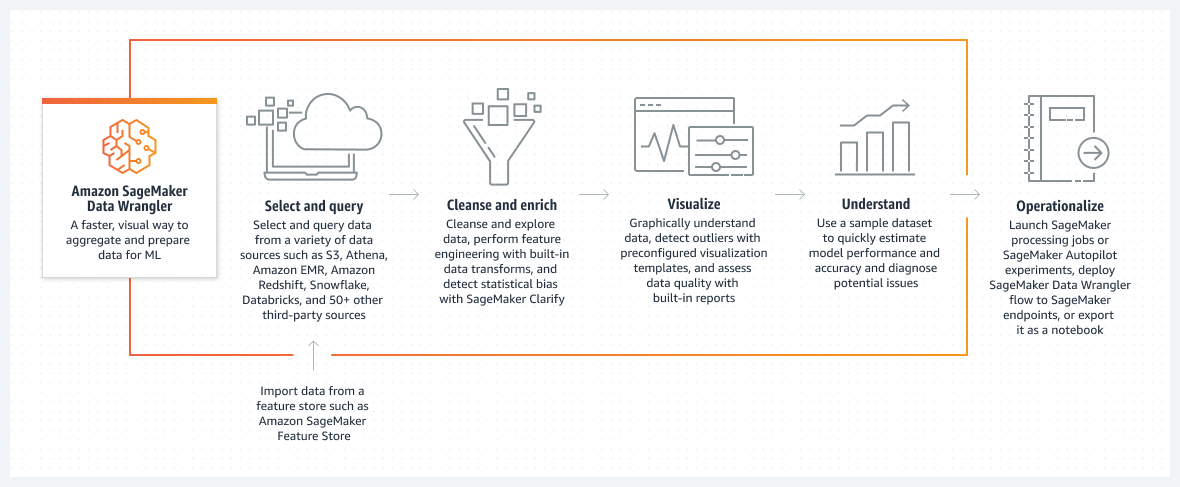
Funcionamiento

Título 1: Amazon SageMaker Data Wrangler
Texto descriptivo: Una forma más rápida y visual de agregar y preparar los datos para el ML
Título 2: Selección y consulta
Texto descriptivo: Seleccione y consulte datos de una variedad de orígenes de datos, como Amazon S3, Athena, Amazon EMR, Amazon Redshift, Snowflake, Databricks y más de 50 orígenes de terceros
Subdescripción: Importe datos desde un almacén de características como Amazon SageMaker
Título 3: Limpieza y enriquecimiento
Texto descriptivo: Limpie y explore los datos, realice ingeniería de características con transformaciones de datos incorporadas y detecte el sesgo estadístico con SageMaker Clarify
Título 4: Visualización
Texto descriptivo: Comprenda gráficamente los datos, detecte los valores atípicos con plantillas de visualización preconfiguradas y evalúe la calidad de los datos con informes incorporados
Título 5: Comprensión
Texto descriptivo: Utilice un conjunto de datos de muestra para estimar rápidamente el rendimiento y precisión del modelo y diagnosticar posibles problemas
Título 6: Operacionalización
Texto descriptivo: Inicie los trabajos de procesamiento de SageMaker o los experimentos de SageMaker Autopilot, implemente el flujo de SageMaker Data Wrangler en los puntos de conexión de SageMaker o expórtelo como cuaderno.
Acceso a los datos y selección y consulta de datos con mayor rapidez
Con SageMaker Data Wrangler, puede acceder rápidamente a datos tabulares, texto e imágenes de los servicios de Amazon, como S3, Athena, Redshift y más de 50 fuentes de terceros. Puede seleccionar datos con el generador visual de consultas, escribir consultas SQL o importar datos directamente en varios formatos, como CSV y Parquet.

Generación de información sobre los datos e información sobre su calidad
SageMaker Data Wrangler proporciona un informe de calidad de datos e información que verifica automáticamente la calidad de los datos (como los valores que faltan, filas duplicadas y tipos de datos) y ayuda a detectar anomalías (como valores atípicos, desequilibrio de clases y fuga de datos) en sus datos. Tras verificar eficazmente la calidad de los datos, puede aplicar rápidamente el conocimiento del dominio para procesar conjuntos de datos para el entrenamiento de modelos de ML.

Información de los datos con visualizaciones
SageMaker Data Wrangler lo ayuda a comprender los datos mediante sólidas plantillas de visualización integradas, como histogramas, gráficos de dispersión, importancia de las características y correlaciones. Acelere la exploración de datos con informes intuitivos sobre la calidad de los datos que detectan anomalías en los tipos de datos y ofrecen recomendaciones para mejorar la calidad de los datos.

Transformación de los datos de manera más eficiente
SageMaker Data Wrangler ofrece más de 300 transformaciones de PySpark prediseñadas y una interfaz de lenguaje natural para preparar datos tabulares, series temporales, texto e imágenes sin necesidad de codificación. Se cubren casos de uso comunes como vectorizar texto, destacar la fecha y hora, codificar, equilibrar datos o aumentar imágenes. También puede crear transformaciones personalizadas en PySpark, SQL y Pandas o usar la interfaz de lenguaje natural para generar código. Una biblioteca integrada de fragmentos de código simplifica la escritura de transformaciones personalizadas.

El poder predictivo de los datos
SageMaker Data Wrangler proporciona un análisis de modelo rápido para estimar el poder predictivo de sus datos. Obtiene la precisión estimada del modelo, la importancia de las características y una matriz de confusión para ayudarlo a validar la calidad de los datos antes de entrenar los modelos.

Automatice y despliegue los flujos de trabajo de preparación de datos de ML
SageMaker Data Wrangler le permite escalar para preparar petabytes de datos sin tener que programar PySpark ni crear clústeres. Inicie trabajos de procesamiento directamente desde la interfaz de usuario o integre la preparación de datos en los flujos de trabajo de ML al exportar los datos a SageMaker Feature Store o integrándolos con SageMaker Pipelines. También puede exportar los flujos de datos como cuadernos de Jupyter o secuencias de comandos de Python para la replicación programática de los pasos de preparación de los datos.

Clientes
“En INVISTA, nos impulsa la transformación y nos enfocamos en desarrollar productos y tecnologías que beneficien a clientes de todo el mundo. Consideramos el ML como una forma de mejorar la experiencia del cliente. Pero, con conjuntos de datos que abarcan cientos de millones de filas, necesitábamos una solución que nos ayudara a preparar los datos y desarrollar, implementar y administrar a escala modelos de ML. Con Amazon SageMaker Data Wrangler, ahora podemos seleccionar, borrar, explorar y comprender nuestros datos de forma interactiva de forma eficaz, lo que permite a nuestro equipo de ciencia de datos crear canalizaciones de ingeniería de características que se pueden escalar sin esfuerzo a conjuntos de datos que abarcan cientos de millones de filas. Con Amazon SageMaker Data Wrangler, podemos poner en funcionamiento nuestros flujos de trabajo de ML con mayor rapidez”.
Caleb Wilkinson, Former Lead Data Scientist de INVISTA
“Con el uso del ML, 3M está mejorando los productos de eficacia probada, como el papel de lija, e innovando en muchos otros ámbitos, como el sanitario. A medida que planeamos escalar el proceso de ML en más áreas de 3M, vemos cómo la cantidad de datos y modelos crecen rápidamente y se multiplican año tras año. Estamos entusiasmados con las nuevas características de SageMaker porque nos ayudarán a escalar. Amazon SageMaker Data Wrangler facilita la preparación de datos para el entrenamiento de modelos, y Almacén de características de Amazon SageMaker elimina la necesidad de crear repetidamente las mismas características del modelo. Por último, Canalizaciones de Amazon SageMaker nos ayudará a automatizar la preparación de datos y la creación e implementación de modelos en un flujo de trabajo integral, para así poder acelerar el tiempo de comercialización de nuestros modelos. Nuestros investigadores esperan aprovechar el nuevo ritmo de la ciencia en 3M”.
David Frazee, Former Technical Director en Corporate Systems Research Lab de 3M
“Amazon SageMaker Data Wrangler nos permite abordar las necesidades de preparación de datos con una gran colección de herramientas de transformación que aceleran el proceso de preparación de datos de ML necesario para llevar nuevos productos al mercado. A su vez, nuestros clientes se benefician del ritmo al que escalamos los modelos implementados, lo que nos permite ofrecer resultados medibles y sostenibles que satisfagan las necesidades de los clientes en cuestión de días en lugar de meses”.
Frank Farrall, Principal, AI Ecosystems and Platforms Leader de Deloitte
“Como socio consultor premier de AWS, nuestros equipos de ingeniería están trabajando en conjunto con AWS para crear soluciones innovadoras a fin de ayudar a los clientes a mejorar de forma continua la eficacia de sus operaciones. El ML es la base de nuestras soluciones innovadoras, pero el flujo de trabajo de preparación de datos conlleva técnicas de preparación de datos sofisticadas que, como resultado, tardan bastante tiempo en rendir de forma operativa en un entorno de producción. Con Amazon SageMaker Data Wrangler, nuestros científicos de datos pueden completar todos los pasos del flujo de trabajo de preparación de datos, incluida la selección, limpieza, exploración y visualización de datos, lo que nos ayuda a acelerar el proceso de preparación de datos y a preparar con facilidad los datos para el ML. Gracias a Amazon SageMaker Data Wrangler, podemos preparar más rápidamente datos para el ML”.
Shigekazu Ohmoto, Senior Corporate Managing Director de NRI Japan
“A medida que nuestra presencia en el mercado de la administración sanitaria de la población continúa expandiéndose a más pagadores, proveedores, administradores de beneficios de farmacia y otras organizaciones sanitarias, necesitábamos una solución que permitiera automatizar los procesos de manera integral para los orígenes de datos que alimentan nuestros modelos de ML, incluidos los datos de reclamos, inscripciones y farmacia. Con Amazon SageMaker Data Wrangler, ahora podemos acelerar el tiempo que toma agregar y preparar los datos para el ML mediante un conjunto de flujos de trabajo que son más fáciles de validar y reutilizar. Esto ha mejorado de manera considerable el tiempo de entrega y la calidad de nuestros modelos, ha aumentado la eficacia de nuestros científicos de datos y ha reducido en casi un 50 % el tiempo de preparación de datos. Además, SageMaker Data Wrangler nos ha permitido ahorrar iteraciones de ML y bastante tiempo de GPU, lo que aceleró todo el proceso de principio a fin para nuestros clientes, ya que ahora podemos crear mercados de datos con miles de características, incluidas las de farmacia, códigos de diagnósticos, visitas a sala de urgencias, estadías en el hospital, así como otros determinantes demográficos y sociales. Gracias a SageMaker Data Wrangler, podemos transformar datos con una eficacia superior para crear conjuntos de datos de entrenamiento, generar conocimientos sobre los datos antes de ejecutar los modelos de ML y preparar los datos del mundo real para la inferencia y predicción a escala”.
Lucas Merrow, CEO de Equilibrium Point IoT
Introducción a SageMaker Data Wrangler
Blogs
Videos
AWS re:Invent 2023: Democratize ML with no code/low code using Amazon SageMaker Canvas (AIM217)
AWS re:Invent 2023: New LLM capabilities in Amazon SageMaker Canvas, with Bain & Company (AIM363)
Novedades
- Fecha (de más reciente a más antigua)