



什么是数据标注?
在机器学习中,数据标注流程用于识别原始数据(图片、文本文件、视频等)并添加一个或多个有意义的信息标签以提供上下文,从而使机器学习模型能够从中进行学习。例如,标签可指示相片是否包含鸟或汽车、录音中有哪些词发音,或者 X 影像是否包含肿瘤。各种使用案例都需要用到数据标记,包括计算机视觉、自然语言处理和语音识别。
数据标记的工作原理
今天,最实用的机器学习模型利用的是监督学习,它应用算法以将一个输入映射到一个输出。为了使监督学习发挥作用,您需要一组带标签的数据,使模型能够从中学习以做出正确的决定。数据标记的起点通常是要求人类就指定的无标签数据做出判断。例如,标记者可能需要为数据集中“相片是否包含鸟”的答案为“是”的所有图片添加标签。添加标签可能像简单的是/否一样粗疏,也可能像识别图片中与鸟相关的像素一样精细。机器学习模型在名为“模型训练”的流程中,使用人类提供的标签学习背后的模式。 这样训练过的模型,可用于对新数据进行预测。
在机器学习中,您用作客观标准来训练和评估指定模型的正确标记的数据集通常称为“标准答案”。 训练过的模型的准确度将取决于标准答案的准确度,因此请付出一些时间和资源来确保高准确度的数据标记至关重要。
数据标记的常见类型有哪些?
计算机视觉
构建计算机视觉系统时,首先需要标记图片、像素或关键点,或者创建完全包围数字图片的界限(称为边界框),以生成训练数据集。例如,您可以按质量类型(例如,产品与生活方式图片)或内容(图片自身实际包含的内容)对图片进行分类,也可以在指定的像素级别分割图片。然后,您可以使用这些训练数据构建计算机视觉模型,该模型可用于自动对图片进行分类、检测对象的位置、识别图片中的关键点,或分割图片。
自然语言处理
自然语言处理要求您首先手动识别文本中的重要部分或使用特定标签来标记文本,以生成您的训练数据集。例如,您可能想要确定文本广告的观点或意图、识别语音中的部分、归类地点和人名之类的专有名词,并识别图片、PDF 或其他文件中的文字。为此,您可以在文字周围绘制边界框,然后手动将这些文字转录到训练数据集。自然语言处理模型用于情感分析、实体名称识别和光学字符识别。
音频处理
音频处理可以将所有类型的声音,例如语音、野生动物噪音(吠声、嚎叫或鸟鸣)和建筑声音(打碎玻璃、扫描或警报),转换成结构化格式,以便用于机器学习。音频处理通常要求您首先手动将其转录为书面文本。然后,您可以通过添加标签并对音频进行分类,找出关于该音频的更深层的信息。这种经过分类的音频成为您的训练数据集。
数据标记的最佳实践有哪些?
有许多技巧可用于提高数据标记的效率和准确性。其中包括:
- 直观且流线化的任务界面有助于尽可能减少人类标记者的认知负荷和上下文转换。
- 标记者共识有助于抵消注释人员个体的误差/偏见。标记者共识涉及将每个数据集对象发送给多个注释人员,然后将他们的响应(称为“注释”)合并到单个标签中。
- 标签审计用于验证标签的准确性,并根据需要对其进行更新。
- 主动学习可利用机器学习识别人类应标记的最有用的数据,使数据标注更加高效。
如何高效地完成数据标记?
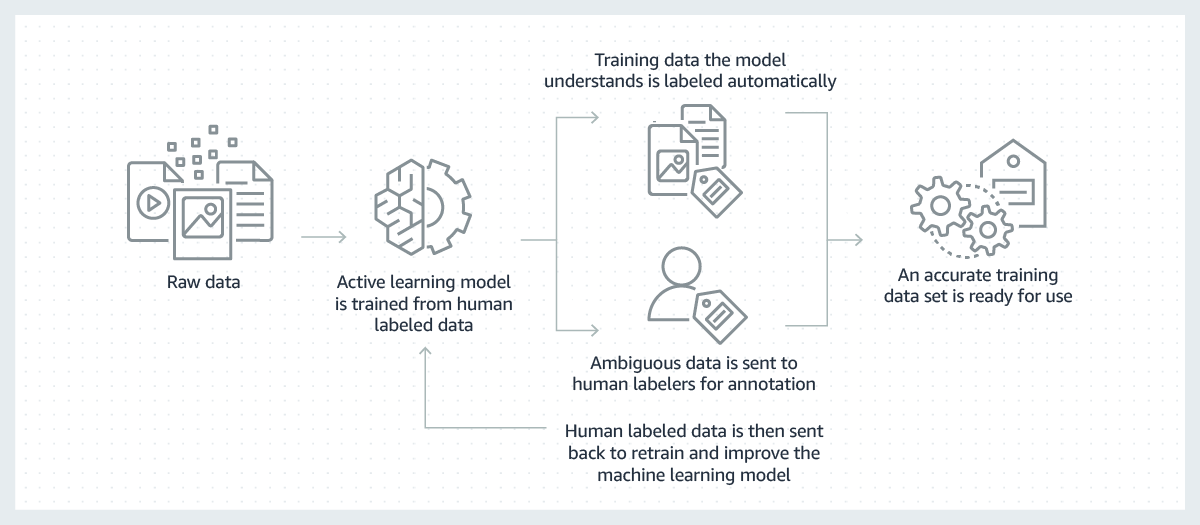
成功的机器学习模型建立在大量高质量训练数据的基础之上。但是,创建构建这些模型所需的培训数据的过程通常十分昂贵、复杂和耗时。今天创建的大多数模型都需要人工以手动方式标记数据,从而使模型学习如何做出正确决策。为了应对这种挑战,可以利用机器学习模型自动标记数据,以使标记更加高效。
在此流程中,先在由人类标记的原始数据子集上训练用于标记数据的机器学习模型。如果标记模型基于其迄今所学的内容认为其结果的置信度较高,则它将自动将标签应用于原始数据。如果标记模型认为其结果置信度较低,它会将数据传递给人工标识器进行标记。然后,将人类生成的标签反馈给标记模型供其从中学习,并提高其自动标记下一组原始数据的能力。随着时间的推移,该模型可以自动标记越来越多的数据,并大大加快创建培训数据集的速度。
AWS 如何满足您的数据标注要求?
Amazon SageMaker Ground Truth 大大减少了为训练创建数据集所需的时间和精力。SageMaker Ground Truth 可访问公有和私有人工标识器,并为它们提供常见标记任务的内置工作流和界面。轻松地上手 Amazon SageMaker Ground Truth。利用入门教程,在几分钟内就能创建您的第一个标记作业。
立即创建账户,开始使用 AWS 上的数据标注。