Containers
How H2O.ai optimized and secured their AI/ML infrastructure with Karpenter and Bottlerocket
This post was co-written with Ophir Zahavi, Cloud Engineering Manager, H2O.ai
Introduction
H2O.ai is a visionary leader in democratizing artificial intelligence (AI) by rapidly provisioning AI platforms that help businesses make better decisions. Our company’s SaaS platform, built on AWS, H2O AI Managed Cloud, enables businesses to build productive models and gain insights from their data quickly and easily.
H2O.ai’s platform uses data and technology to improve:
- Speed: Our platform helps businesses to quickly develop and deploy AI/ML models, which leads to faster time to market and improved decision-making.
- Accuracy: Our platform uses a variety of techniques to improve the accuracy of AI/ML models, including automatic feature engineering and model selection.
- Scalability: Our platform can be scaled to handle large datasets and complex problems.
- Explainability: Our platform provides insights into how AI/ML models make decisions, which can help businesses to trust and adopt these models.
This post demonstrates how we used Karpenter, an AWS open-sourced just-in-time Kubernetes autoscaler, and Bottlerocket, a secure, lightweight, purpose-built Linux-based operating system to run containers in the Amazon Elastic Kubernetes Service (Amazon EKS) clusters. This combined functionality, along with prefetching container images, helped us improve the compute provisioning and configuration time for our ML workloads by 100-fold.
Challenges
- We used the Kubernetes Cluster Autoscaler to automatically adjust the number of nodes in our tenant clusters when deploying new ML workloads. The Kubernetes Cluster Autoscaler worked with Auto Scaling groups to scale compute capacity of the managed node groups . For more information, see Cluster Autoscaler on AWS.
The Cluster Autoscaler was set up for multiple node groups with various instance families and size configurations. This was needed to provide the correct compute node according to the use case e.g., ML data training, inference, or running arbitrary workloads. This process was time-consuming and error-prone and added complexity in managing infrastructure and deployment of workloads.

Figure 1: Amazon EKS Cluster with Kubernetes Autoscaler
- We used Amazon Linux 2 for our worker nodes host operating system (OS). However, our operational workflows to run containers doesn’t involve installing software on the host OS, nor do we need to directly ssh into instances, or run third-party ISV software that isn’t containerized (e.g., agents for logging and monitoring). Additionally, we were looking to improve resource usage and reduce the attack surface on the host OS.
- As part of our managed cloud SaaS solution, we deploy ML services that have large-sized container images. When images grow beyond a few hundred MBs, it can take several minutes just to start a container. The primary reason for this slowness is that the container runtime must pull the entire container image before the container can start.
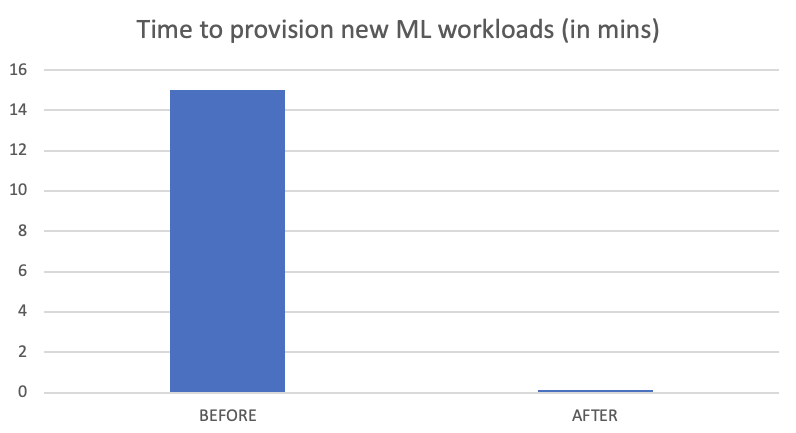
The above challenges caused a high turnaround time when provisioning ML workloads. It often took 15 minutes or more to provision new workloads. We wanted to reduce this provisioning time drastically.
Solution overview
Our cloud engineering team worked with the AWS account team and AWS WWSO specialists. After considering several options, experimentation, and testing, we addressed the challenges above by choosing Karpenter for scaling nodes and Bottlerocket OS in our node template amiFamily configuration.
The following flow outlines the steps taken:
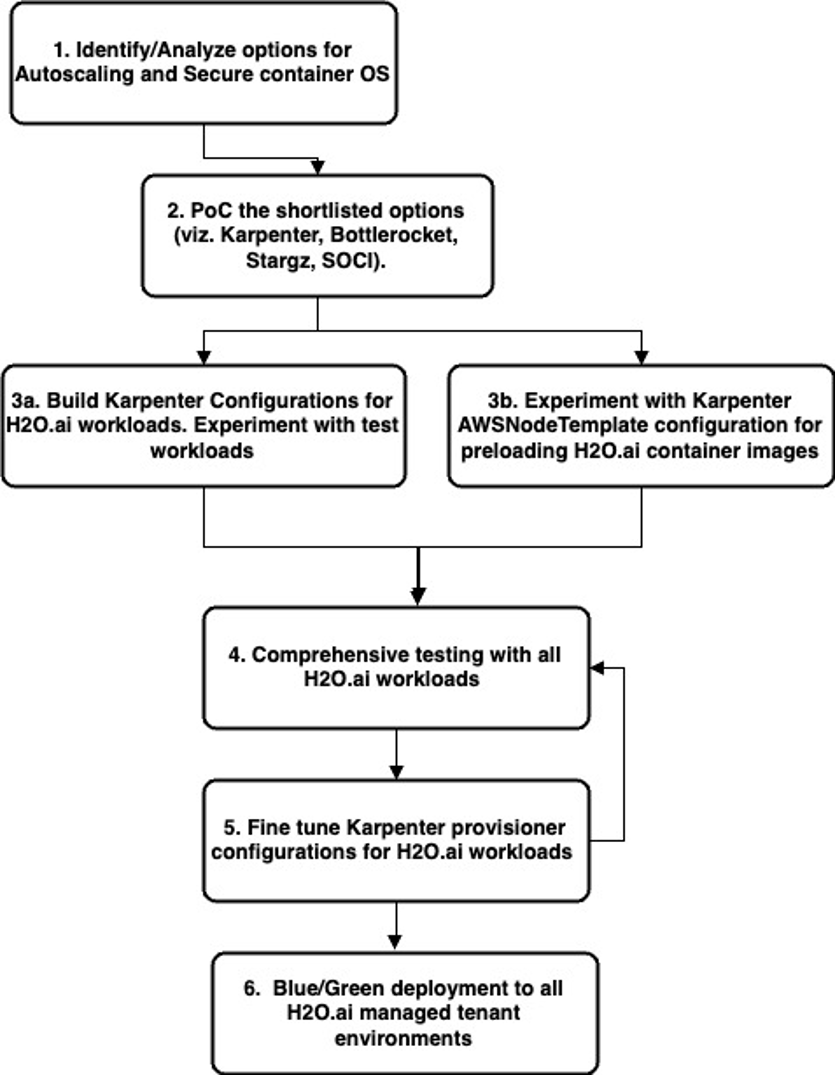
Figure 2: High-level steps for our solution implementation
For prefetching our large container images, we considered stargz and seekable OCI (SOCI). Neither stargz nor SOCI offered an easy-to-use solution. Alternately, Karpenter’s AWS NodeTemplate with Bottlerocket OS provided an easy-to-use functionality to use existing pre-baked disks that included all needed container images for the newly created instance by Karpenter. After configuring Karpenter and Bottlerocket, we ran validation tests for the combined functionality with our ML workload. After initial success in validation tests, we ran a comprehensive test for all of our workloads which make up the managed cloud SaaS solution environment. Based on the feedback, we iterated multiple times to fine-tune the Karpenter provisioner configurations. We also measured the time taken for provisioning workloads and were pleasantly surprised with the results.
Walkthrough
- We chose Karpenter, a just-in-time, group-less nodes auto-scaler, to improve the provisioning and configuration of Kubernetes clusters for our Managed Cloud SaaS solution.
![Walkthrough 1. We chose Karpenter, a just-in-time, group-less nodes auto-scaler, to improve the provisioning and configuration of Kubernetes clusters for our Managed Cloud SaaS solution. Figure 3: Amazon EKS cluster with Karpenter Autoscaler Karpenter provisioner is a Kubernetes custom resource to provision nodes with optional attributes (taints, labels, requirements, time-to-live, etc.). A single provisioner can manage compute for multiple workloads. We created multiple provisioners, which enabled the functionality to instantiate the right compute node based on the workload requirements (e.g., ML training jobs, ML inferencing tasks, etc). Multiple provisioners were created for a couple of reasons: ● Using weighted provisioners in Karpenter, we were able to deterministically attempt to schedule certain graphical process unit(GPU) instances first. This enabled us to prefer GPU instances for certain workloads and, at the same time, not be affected by GPU instances availability. This was done with a provisioner configuration similar to the one below. Notice that we have given our custom provisioner a higher weight than the default one weight: 2. We also instructed the custom Provisioner to use only GPU instances categories. apiVersion: karpenter.sh/v1alpha5 kind: Provisioner metadata: name: weight-provisioner-for-gpu spec: providerRef: name: weight-provisioner-for-gpu ttlSecondsAfterEmpty: 30 weight: 2 labels: my-label: weight-provisioner-for-gpu requirements: - key: karpenter.k8s.aws/instance-category operator: In values: [“p", “g"] - key: karpenter.k8s.aws/instance-generation operator: Gt values: ["2"] ● To enable picking the correct instance type according to the workload (e.g., inference, or platform workloads). In this custom provisioner, we configured the provisioner to only launch nodes which specifically satisfy a specific workload requirement. In this example, it is the instance-type which would be of family “t”. Provisioner spec: requirements: - key: "karpenter.k8s.aws/instance-category" operator: In values: ["t"] - key: "kubernetes.io/arch" operator: In values: ["amd64"] Deployment spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node.kubernetes.io/instance-type operator: In values: - t3.micro This made it possible for us to use the best available compute and rapidly scale our SaaS tenant infrastructure up or down as needed, which improved the performance and reliability of our SaaS platform. 2. We chose Bottlerocket container OS as the default OS for our Kubernetes worker nodes. Bottlerocket is a secure, lightweight container OS designed for use in production environments. The base operating system has just what you need to run containers reliably and is built with standard open-source components. Bottlerocket-specific additions focus on reliable updates and the API. Instead of making configuration changes manually, you can change settings with an API call, and these changes are automatically migrated through updates. The Amazon machine image (AMI )used when provisioning nodes can be controlled by the amiFamily field in the NodeTemplate configuration. Based on the value set for amiFamily, Karpenter will automatically query for the appropriate EKS-optimized AMI via AWS Systems Manager (SSM). By choosing Bottlerocket, we improved resource usage, reduced the risk of security vulnerabilities, and improved the overall security of our SaaS platform. Additionally, since the latest Amazon EKS-optimized AMI is queried each time a node was instantiated by Karpenter, which reduced our operational overhead of patching the OS. Our worker nodes were frequently scaled up and down which ensured the AMI drift was minimal to none. Bottlerocket runs two completely separate container runtimes: - One for orchestrator containers (for e.g., to run Kubernetes pods) - Another for host containers (for e.g., to perform operational tasks) Bootstrap containers are host containers that can be used to bootstrap the host before services like kubelet, and containerd/docker start. Bootstrap containers are very similar to normal host containers. They come with persistent storage and optional user data. We made use of the Bootstrap containers to implement the CIS Benchmark for Bottlerocket. For further information, please refer this AWS post. 3. The blockDeviceMappings field in an AWSNodeTemplate can be used to control the Amazon Elastic Block Storage (Amazon EBS) volumes that Karpenter attaches to provisioned nodes. Karpenter uses default block device mappings for the AMI Family specified. For example, the Bottlerocket AMI Family defaults with two block device mappings: one for Bottlerocket’s control volume and the other for container resources such as images and logs. We used the later block device mapping for our large ML container images. As you can see in the configuration below, the xvdb disk is created from a snapshot that already includes our container images.](https://d2908q01vomqb2.cloudfront.net/fe2ef495a1152561572949784c16bf23abb28057/2023/07/27/Karpenter-Autoscaler.png)
Figure 3: Amazon EKS cluster with Karpenter Autoscaler
Karpenter provisioner is a Kubernetes custom resource to provision nodes with optional attributes (taints, labels, requirements, time-to-live, etc.). A single provisioner can manage compute for multiple workloads. We created multiple provisioners, which enabled the functionality to instantiate the right compute node based on the workload requirements (e.g., ML training jobs, ML inferencing tasks, etc).
Multiple provisioners were created for a couple of reasons:
- Using weighted provisioners in Karpenter, we were able to deterministically attempt to schedule certain graphical process unit(GPU) instances first. This enabled us to prefer GPU instances for certain workloads and, at the same time, not be affected by GPU instances availability. This was done with a provisioner configuration similar to the one below. Notice that we have given our custom provisioner a higher weight than the default one weight: 2. We also instructed the custom Provisioner to use only GPU instances categories.
- To enable picking the correct instance type according to the workload (e.g., inference, or platform workloads). In this custom provisioner, we configured the provisioner to only launch nodes which specifically satisfy a specific workload requirement. In this example, it is the instance-type which would be of family “t”.
Provisioner spec:
Deployment spec:
This made it possible for us to use the best available compute and rapidly scale our SaaS tenant infrastructure up or down as needed, which improved the performance and reliability of our SaaS platform.
2. We chose Bottlerocket container OS as the default OS for our Kubernetes worker nodes. Bottlerocket is a secure, lightweight container OS designed for use in production environments. The base operating system has just what you need to run containers reliably and is built with standard open-source components. Bottlerocket-specific additions focus on reliable updates and the API. Instead of making configuration changes manually, you can change settings with an API call, and these changes are automatically migrated through updates.
The Amazon machine image (AMI )used when provisioning nodes can be controlled by the amiFamily field in the NodeTemplate configuration. Based on the value set for amiFamily, Karpenter will automatically query for the appropriate EKS-optimized AMI via AWS Systems Manager (SSM).
By choosing Bottlerocket, we improved resource usage, reduced the risk of security vulnerabilities, and improved the overall security of our SaaS platform. Additionally, since the latest Amazon EKS-optimized AMI is queried each time a node was instantiated by Karpenter, which reduced our operational overhead of patching the OS. Our worker nodes were frequently scaled up and down which ensured the AMI drift was minimal to none.
Bottlerocket runs two completely separate container runtimes:
- One for orchestrator containers (for e.g., to run Kubernetes pods)
- Another for host containers (for e.g., to perform operational tasks)
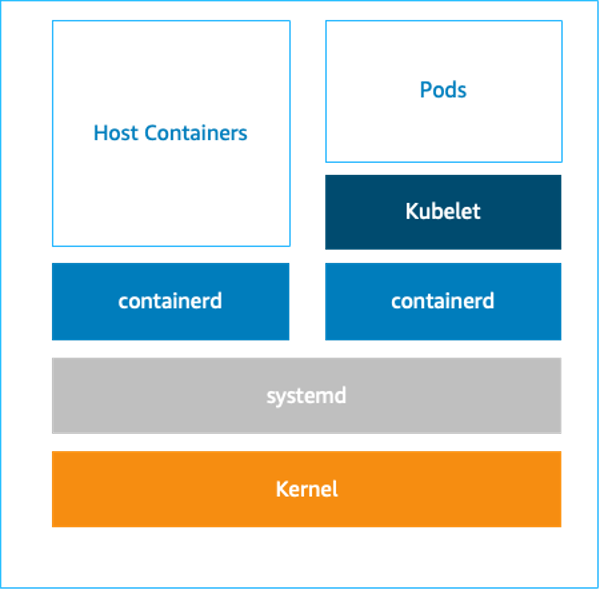
Bootstrap containers are host containers that can be used to bootstrap the host before services like kubelet, and containerd/docker start. Bootstrap containers are very similar to normal host containers. They come with persistent storage and optional user data. We made use of the Bootstrap containers to implement the CIS Benchmark for Bottlerocket. For further information, please refer this AWS post.
3. The blockDeviceMappings field in an AWSNodeTemplate can be used to control the Amazon Elastic Block Storage (Amazon EBS) volumes that Karpenter attaches to provisioned nodes. Karpenter uses default block device mappings for the AMI Family specified. For example, the Bottlerocket AMI Family defaults with two block device mappings: one for Bottlerocket’s control volume and the other for container resources such as images and logs. We used the later block device mapping for our large ML container images. As you can see in the configuration below, the xvdb disk is created from a snapshot that already includes our container images.
Results
Using Karpenter, Bottlerocket, and prefetching container images, we reduced our Managed Cloud SaaS solution workload turn-around time from 15 minutes to a few seconds (100x improvement). This was possible due to Karpenter, which enabled on-demand, fast scale up or down our tenant infrastructure while abstracting the configurations needed. We also achieved success with Bottlerocket OS, which not only reduced the risk of security vulnerabilities and improved the overall security of our SaaS platform, but also allowed us to prefetch our large container images.
Conclusion
In this post, we showed you how Karpenter and Bottlerocket resulted in significant improvements to the performance, reliability, and security of our H2O.ai SaaS platform. These improvements have helped us serve our customers better and grow our business.
Call to action
If you are a business running Amazon EKS clusters that need improved performance, reliability, and security of your platform, then you should consider using Karpenter and Bottlerocket. The deep functionalities of these tools can help accelerate the provisioning and configuration of Kubernetes clusters, scale your infrastructure up or down as needed, and reduce the risk of security vulnerabilities.

Ophir Zahavi, H2O.ai
Ophir Zahavi is a Cloud Engineering Manager at H2O.ai based in Israel. Ophir has built business-critical systems for enterprises and startups for the past ten years. In addition to his specialization in AWS and Kubernetes, he is passionate about cloud and cloud-native technologies.